本文提出了两种应对长尾分布的方法:
1.提出了一种自适应校准函数对分类器的输出得分进行调整;
2.提出了一种广义重加权校准通过数据集分布的先验信息对损失函数进行了修改;
本文的实验比较充分,做了在图像分类、语义分割、目标检测的实验,均取得了进步。
3.1 Motivation
本文首先通过消融实验探讨了两阶段学习框架的性能瓶颈。下图中黄线使用backbone直接训练得到,绿线先使用backbone训练特征表示器,随后再用平衡的完整数据集重新训练模型的分类器。(具体的平衡的数据集是是怎么采样得到的待与作者确认)
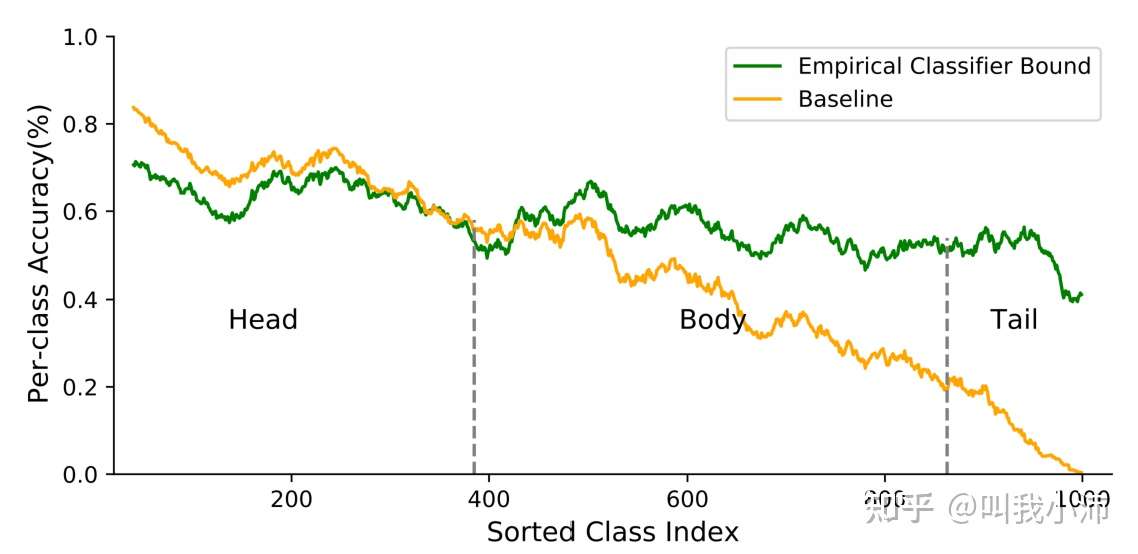
从图中可以看出绿线是比黄线的准确率高的,这说明在第一阶段不平衡数据训练出了良好的表示器,但是第二阶段的分类器训练还有很大的改进空间。
这里的思想实际上就是把BBN里将表示器和分类器解耦的思想换了一种说法。
随后做了这样一个实验:使用三种不同的采样方法(IB、CB、SR)对不平衡的ImageNet-LT进行处理,然后在第一阶段训练特征提取器;随后在第二阶段,同样地使用平衡的ImageNet数据集对分类器进行重新训练,得到下图左边的结果。这个图意在证明即便使用了现有的数据集平衡采样方法,依然跟理想的情况有较大差距。
在下图右边的图中,作者对比了目前最新的一种长尾分布问题的解决方法*(cRT,from CVPR2020)*,并用实验说明了这种方法距离bottle neck是有一定差距的,因此本文的研究是有必要的。
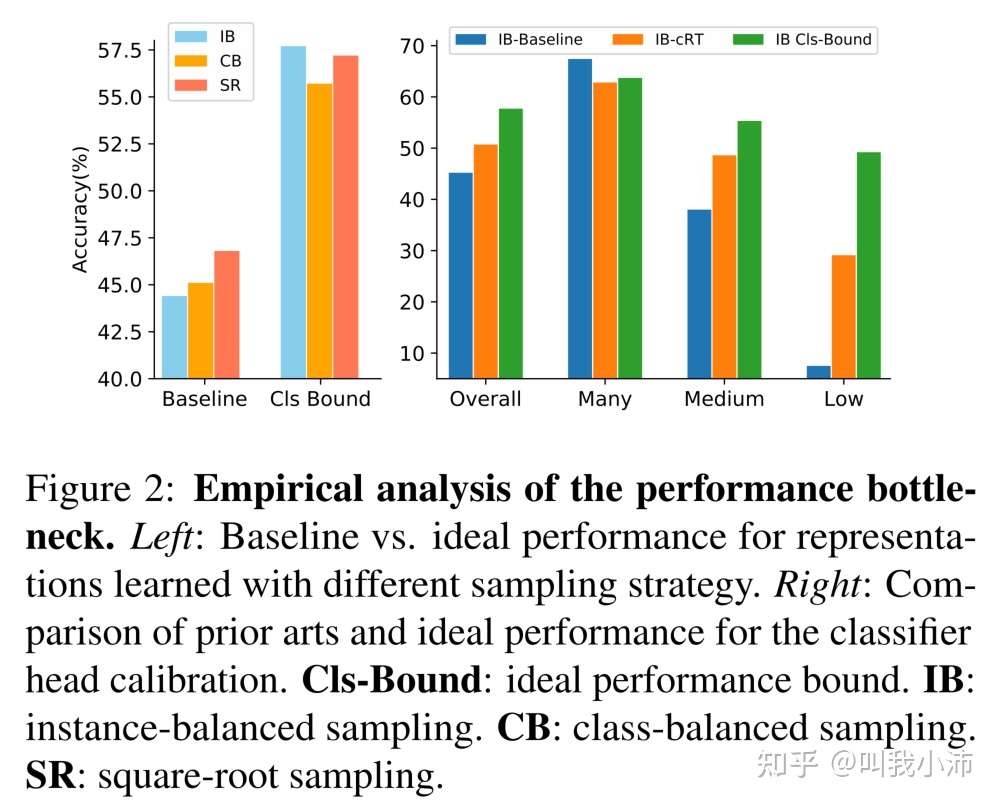
从实验结果中,作者得到了一个结论:在第一阶段特征提取器产生了一个强大的特征表示,而现有长尾方法的性能瓶颈在于特征空间中有偏差的决策边界。
3.2 分布校准
本文提出的方法首先用原始不平衡数据集对模型进行训练;
随后固定特征提取器$f()$不变,对原始分类器头部$h_0()$进行了两种平衡方法(自适应校准函数、广义重加权)以调整分类器的决策边界。
1.自适应校准函数
论文提出了一个自适应校准函数,可以调整每个数据点的分值,具体方法如下:
(1)首先将原始分类器$h_0(*)$输出的类别分数表示为$[z_1^0,\ldots,z_K^0]$,引入了校准参数$\alpha_j、\beta_j$对每个类别的原始分数$z_j^0$进行加权得到$s_j$;
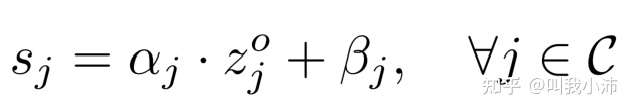
(2)随后用一个置信度得分函数对原始分数$z_j^0$和调整后的分数进行加权:
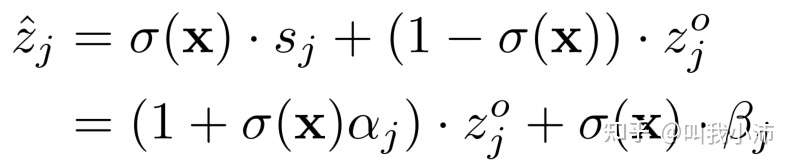
其中置信度σ(x)控制特定输入x需要多少校准,由一个linear层跟一个non-linear层来实现。
(3)之后用softmax函数对新的分数$\hat{z_j}$计算概率分布:
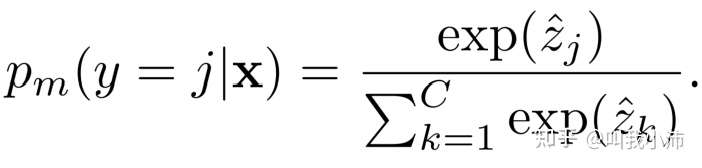
2.广义重加权校准
为了便于理解论文改进了个啥,这里首先复习一下多分类情况下的交叉熵损失的定义:
$$
H(p||q)=-\sum_{y\in C}^{} {p(y)log(q(y))}
$$
其中p(y)是真实概率值(ground truth),q(y)是预测概率值。
而论文中使用了模型预测概率$p_m(*)$和有利于均衡预测的类的参考分布$p_r(y|x)$之间的KL散度作为损失,形式如下:
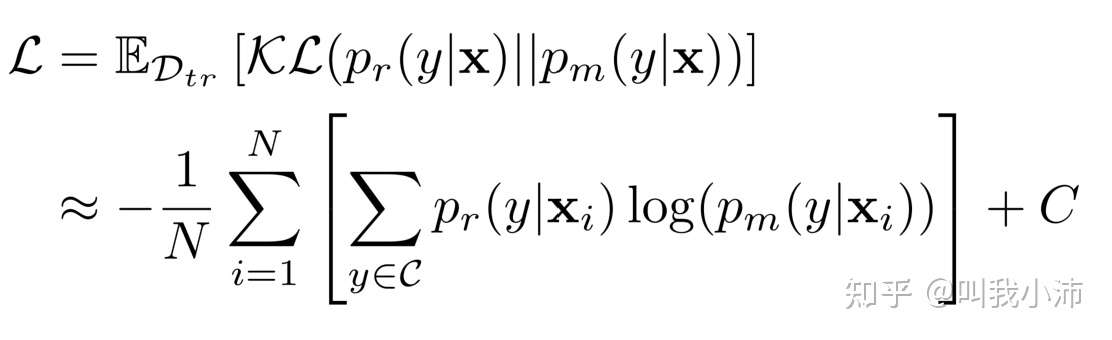
可以看到上面约等的形式其实就还是交叉熵损失函数,加上了一个常数C,把原来的真实概率值换成了下面的形式,并不是KL散度呀(个人理解)。
其中$p_r(y|x)$的定义为:
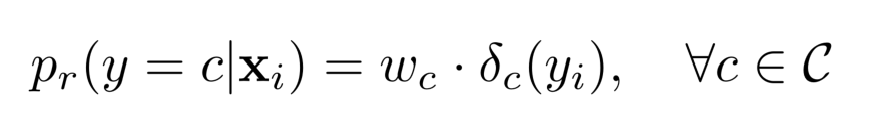
$\delta_c(*)$是一个Kronecker delta函数(当$y_i=c$时值为1,否则值为0);
$w_c$的定义为:
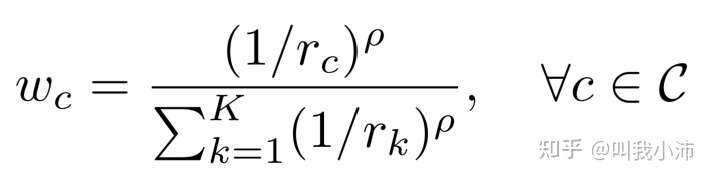
其中ρ是一个比例超参数,用于在编码类之前提供更大的灵活性。注意,当ρ=0时,我们的方案退化为的实例平衡重加权方法;当ρ=1时,退化为类平衡重加权方法。$[r_c,\ldots,r_K]$是作者定义的基于经验类频率的参考权重。
3.3 实验结果
1.图像分类
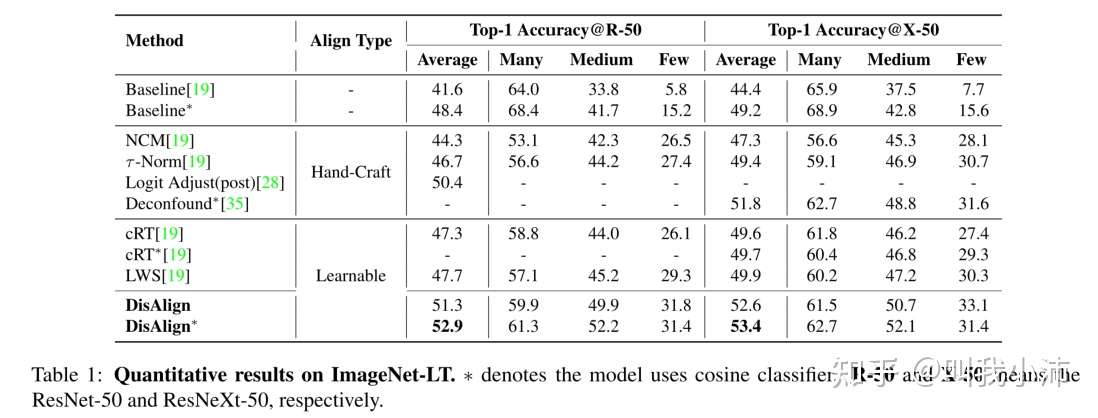
在ImageNet-LT上的实验结果:
backbone:ResNet50、ResNeXt50
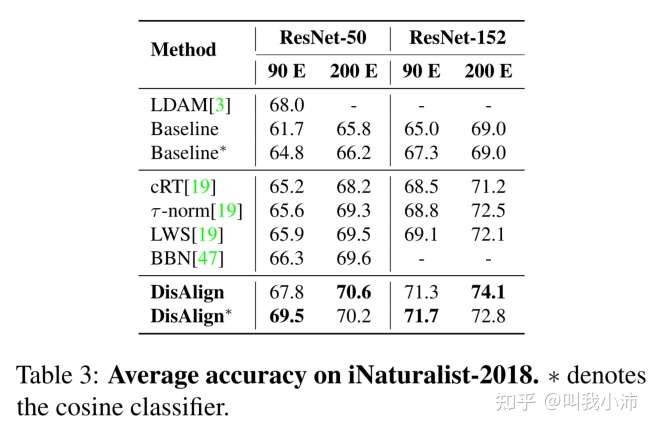
在iNaturalist-2018上的实验结果:
backbone:ResNet50、ResNet152
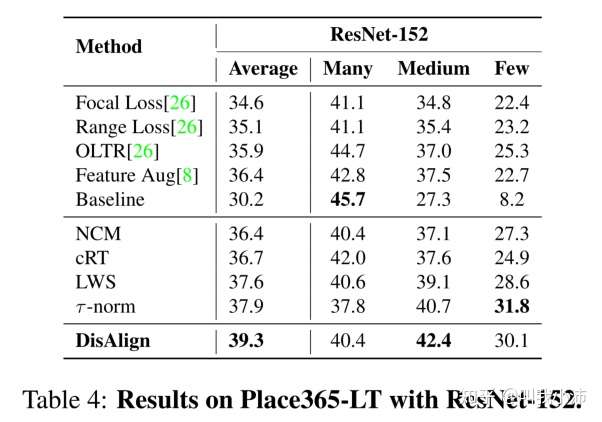
在Place365-LT上的实验结果:
backbone:ResNet-152
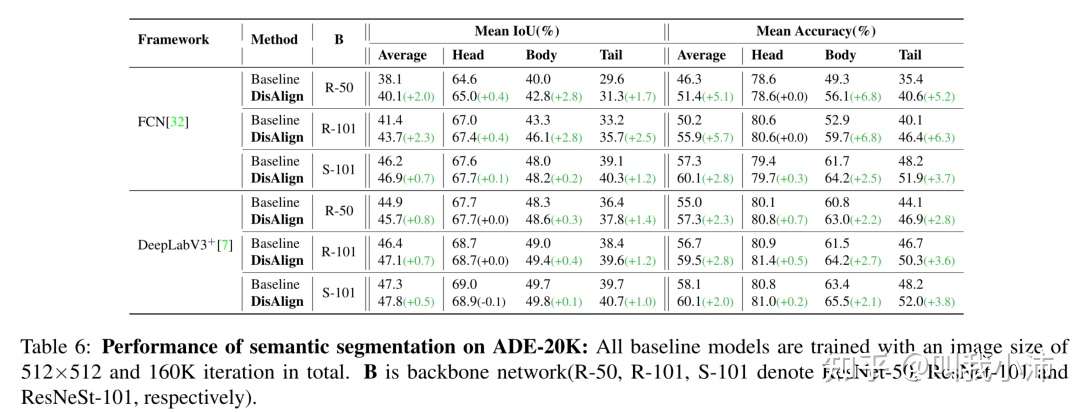
2.语义分割
在ADE-20K上的实验结果:
backbone:ResNet-50、ResNet-101、ResNeSt-101
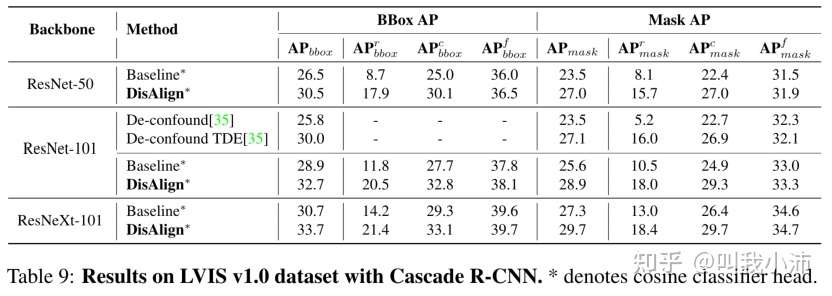
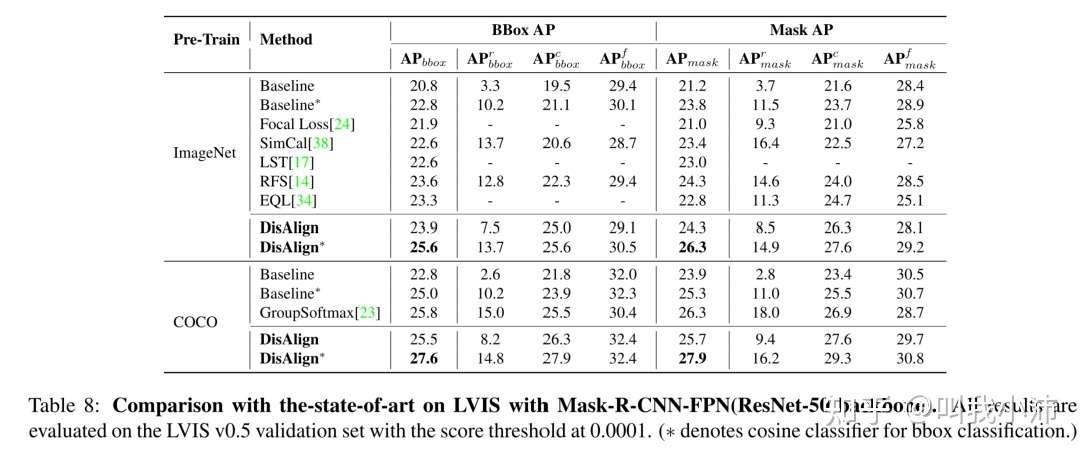
3.目标检测
在LVIS v0.5上的实验结果:
在LVIS v1.0上的实验结果: