这篇CVPR 2021文章出自港中文贾佳亚老师组,值得详细阅读。
当训练数据集严重不平衡时,深层神经网络可能表现不佳。最近,两阶段方法将表示学习和分类器学习解耦以提高性能。但仍有一个至关重要的问题,那就是校准错误。为了解决这个问题,本文设计了两种方法来改进这种场景中的校准和性能。基于类的预测概率分布与类实例的数量高度相关的事实,本文提出了标签感知平滑来处理不同程度的类的过度自信,并改进分类器学习。对于由于不同采样器而导致的这两个阶段之间的数据集偏差,我们进一步在解耦框架中提出了移位批标准化。我们提出的方法在多个流行的长尾识别基准数据集上创造了新记录,包括CIFAR-10-LT、CIFAR-100-LT、ImageNet LT、Places LT和iNaturalist 2018。
9.1 Introduction
长尾分布在真实世界中是广泛存在的,当CNN模型面临长尾分布的数据集时,性能会显著下降。为了解决这个严重的问题,已经有很多长尾识别的方法被提出来了。
最近很多两阶段的方法相对于一阶段的方法来说取得了很大的提升,其思想在于将CNN的表示器和分类器分开训练,先用原始数据集训练CNN的表示器,之后用类别平衡的方法训练分类器。
置信度校准[1,2]通过估计代表真实正确性的可能性来预测概率,对于识别模型来说在很多应用中都很重要。期望校准误差(ECE)被广泛应用于网络的测量校准。为了计算ECE,所有N个预测首先分组到大小相等的B个区间中。ECE的定义如下:
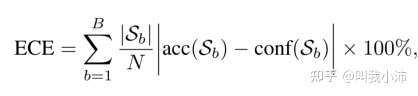
其中$S_b$是预测值落入第$b$个区间的样本集合;$acc(·)$和$conf(·)$分别是$S_b$的准确度和预测置信度。
这里知道ECE是个评估网络校准误差的指标就行;详细可以参考[1,2].
本文的研究表明,由于每个类别的组成比例不平衡,在长尾数据集上训练的网络更容易被错误校准和过度自信。下图是ResNet-32的可靠性图。从左上到右下分别为:在原始平衡CIFAR-100数据集上训练的普通模型、在CIFAR-100-LT(IF=100)上训练的普通模型、在CIFAR-100-LT(IF=100)上使用cRT[3]、在CIFAR-100-LT(IF=100)上使用LWS[3]。从图中可以看出,在长尾数据集上训练的网络通常具有较高的ECE。cRT和LWS的两阶段模型也存在过度自信的问题。
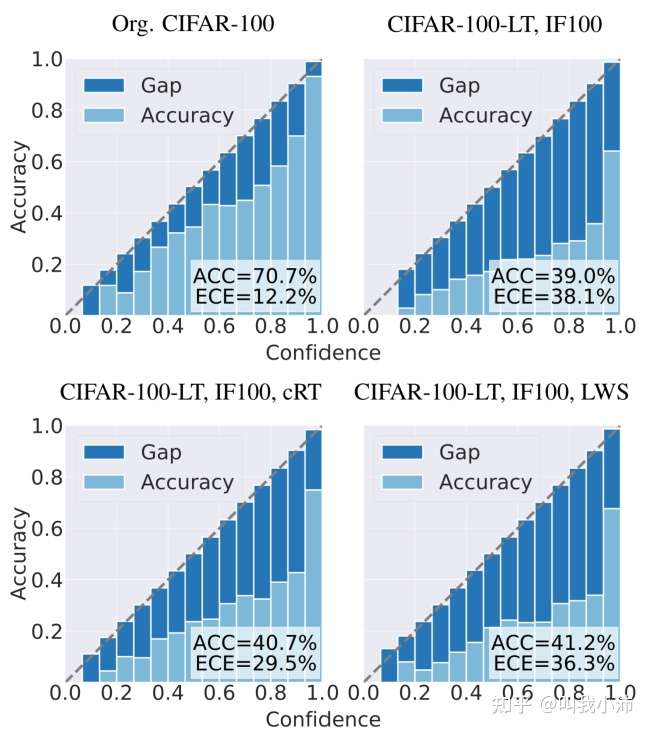
这个图怎么看呢?我的理解是这样:首先浅蓝色是Accuracy,其面积越大ACC也就越大,这点没什么问题;然后图中横坐标是Confidence、纵坐标是Accuracy,我们回头看一眼上面ECE的计算公式,发现acc()和conf()越接近,ECE的值也就越小(ECE越小越好),所以图中深蓝色的部分(即Gap)面积越小,ECE这个指标也就越好。
另外一个问题是,两阶段解耦方法在两个阶段中数据集的分布是不同的(在第一个阶段下使用long-tailed数据集,在第二阶段使用类别平衡采样过的数据集),而现有的方法没有考虑这个问题。
因此,本文提出了一种混合移位标签感知平滑模型(Mixup Shifted Label-Aware Smoothing model,简称MiSLAS)来解决上述问题。
9.2 Related Work
本文的related work总结的还是不错的,这里也记录一下。
1.重采样和重加权
有两种重采样方法:对尾部图像进行过采样和对头部图像进行降采样。过采样通常在大型数据集上很有用,但是可能会造成尾部类过拟合,尤其是在小数据集上。对于欠采样,它会丢弃大量数据,这不可避免地会导致深度模型泛化能力的下降;重加权是另一个重要的方法,它为类甚至实例指定不同的权重,普通的重加权方法给出的类权重与类的样本数成反比。
然而,对于大规模数据集,重加权使得深层模型在训练期间难以优化。Cui等人[4]使用有效样本数来计算类别权重,从而解决了这个问题。另一类工作是自适应地重加权每个实例。例如,focal loss[5]为容易分类的样本分配了较小的权重。
2.置信度校正与正则化
在许多应用中,置信度校准对于分类模型非常重要。模型容量、归一化和正则化对网络校准有很大影响。mixup是一种正则化技术,通过输入和标签的插值进行训练。mixup激发了对manifold mixup、CutMix和Remix的后续研究,这些研究已经显示出显著的改进,经过mixup训练的CNN校准效果更好。Label smoothing 是另一种正则化技术,它鼓励模型减少过度自信。与交叉熵不同的是,交叉熵在ground truth标签上计算损失,Label smoothing 在标签的soft版本上计算损失。它减轻了过拟合,提高了校准度和可靠性。
3.两阶段方法
两阶段方法的思想在于解耦深度CNN模型的表示器和分类器,先用原始数据集训练CNN的表示器,之后用类别平衡的方法训练分类器。
9.3 Main Approach
1.mixup 方法研究
作者研究了在两阶段方法中加入mixup对准确率的影响(文中说的是:“以使表示具有更高的泛化性及降低过度自信 ”,听着就很高大上,学习了)。下表是在ImageNet-LT中对CE、cRT、LWS分别进行实验的结果,打√ 的项表示采用了mixup方法。从下表可以看出,在应用mixup时,CE的改善可以忽略不计,但cRT和LWS的性能都得到了极大的提高;在第2阶段使用额外的mixup不会产生明显的改善,甚至会损害性能。其原因是,mixup鼓励表征学习,但对分类器学习的影响是负面的或可以忽略不计的。
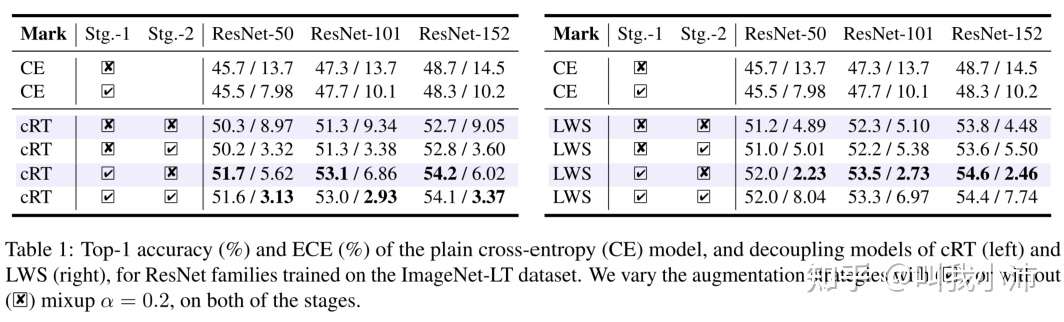
在表1中还列出了上述模型的ECE。当仅在第1阶段中添加mixup时,cRT和LWS模型都可以为不同backbones(第4行和第6行)一致地获得更好的top-1精度和更低的ECEs。由于top-1精度的提高不令人满意,且分类器学习的混和率下降不稳定(通过在第2阶段添加混和),我们提出了一种标签感知平滑,以进一步改进校准和分类器学习。
2.标签感知平滑
文中提出了一种标签感知平滑方法来解决交叉熵和预测概率的变化分布中的过度自信问题。其表示如下:
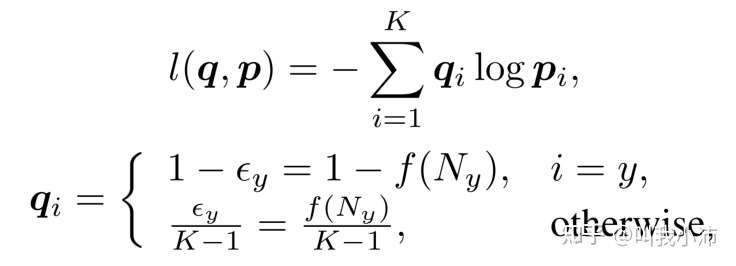
其中$\epsilon_y$是类别$y$(真实类别)的一个小的标签平滑因子,其值与类别$y$的样本数量$N_y$有关。
这个公式相当于在普通的CE上乘了一个因子$q_i$,当类别的数量较多时,$f(N_y)$的值较大,从而对其有一个较大的惩罚,标签从one-hot这样的硬标签,变成了比较软的标签。(idea:可以考虑换用有效类别数量!)
对于普通的交叉熵损失函数,在经过softmax激活之后,损失函数变为: ,其中$y\in {1,2,\cdots,K}$是$K$种类别的标签,$w_i$是第$i$个分类任务的参数。
,其中$y\in {1,2,\cdots,K}$是$K$种类别的标签,$w_i$是第$i$个分类任务的参数。
而对于上面改进的损失函数$l(q,p)$,可以证得:(证明过程详见论文补充材料)
其中c是任意实数。
文中给出了$f(N_y)$的三种形式,分别为:
1)凹形:
2)线性:
3)凸形:
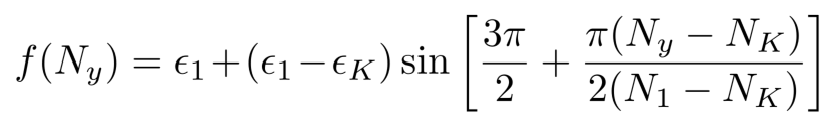
其中$\epsilon_1、\epsilon_K$是两个超参数。
由于标签感知平滑的形式比交叉熵更复杂,文中提出了一个广义分类器学习框架来适应它。文章将cRT和LWS相结合,在第二阶段设计了如下的分类器框架:
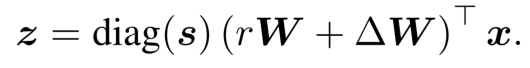
该公式在一定条件下可以分别退化为cRT或LWS的公式。(具体参考论文3.2)
3.基于批量归一化的移位学习
在两阶段训练框架中,首先在第一阶段使用实例平衡采样对模型进行训练,然后在第二阶段使用类平衡采样对模型进行训练。由于该框架涉及两个采样器或两个数据集——实例平衡数据集$D_I$和类平衡数据集$D_C$——我们将此两阶段培训框架视为迁移学习的一个变体。如果我们从迁移学习的角度来看待两阶段解耦训练框架,那么在阶段2中固定主干部分和仅仅调整分类器显然是不合理的,尤其是对于批处理规范化(BN)层。
这个角度很不错,两阶段的学习方法可以看作是先在不平衡的数据集(源域)上进行预训练、然后在平衡的数据集(目标域)上进行微调的方法。
具体而言,假设输入网络为$x_i$,BN层的输入特征为$g(x_i)$,最小批量大小为m。则这两个阶段中通道$j$的平均值和运行方差分别为:
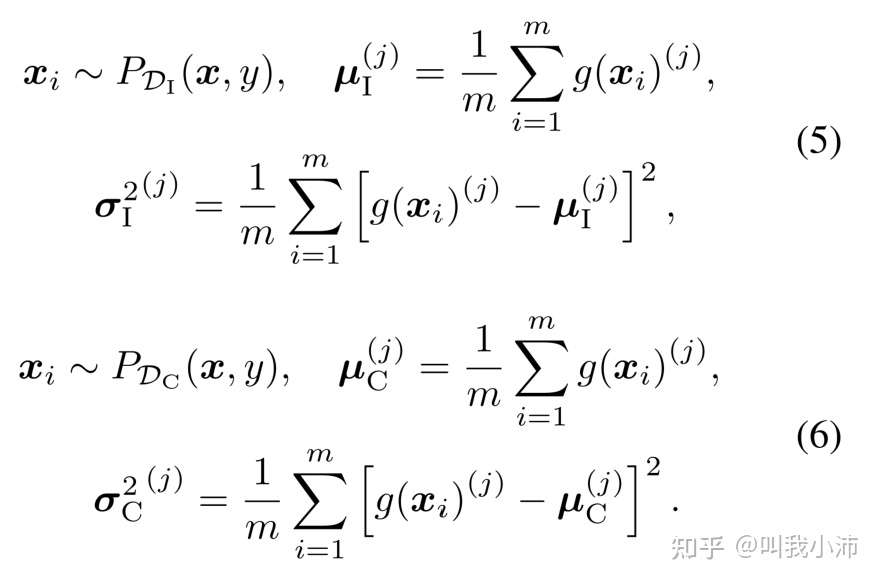
由于两阶段方法中两个阶段的数据集分布并不一样,因此$P_{D_I}(x,y)\neq P_{D_C}(x,y)$.因此,对于解耦框架来说,BN使用两种抽样策略共享数据集的均值和方差是不可行的。受AdaBN和TransNorm的启发,我们更新了运行中的平均值µ和方差σ,同时固定了可学习的线性变换参数α和β,以便在第2阶段更好地进行归一化。
9.4 实验
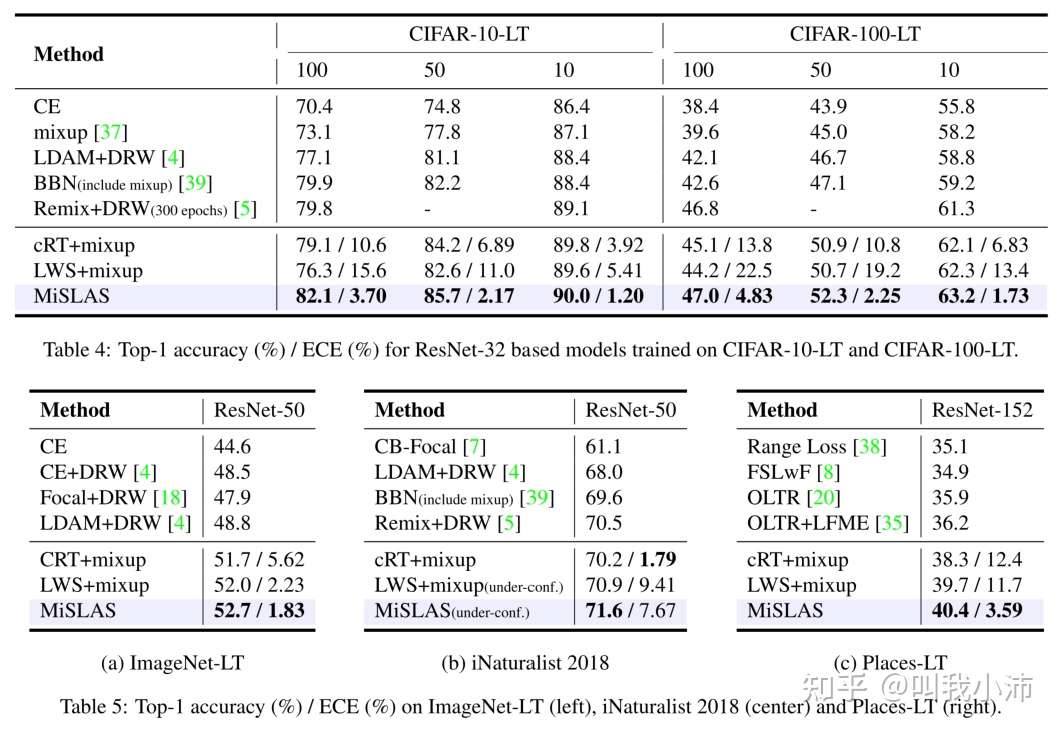
作者在CIFAR-10-LT、CIFAR-100-LT、ImageNet-LT、iNaturalist2018以及Places-LT上和之前的sota方法进行了对比实验,本文所提出的方法在top-1识别精度和置信度校准方面都取得了不错的性能,并取得了新的sota。
[1] Guo C, Pleiss G, Sun Y, et al. On calibration of modern neural networks[C]//International Conference on Machine Learning. PMLR, 2017: 1321-1330.
[2] Niculescu-Mizil A, Caruana R. Predicting good probabilities with supervised learning[C]//Proceedings of the 22nd international conference on Machine learning. 2005: 625-632.
[3] Kang B, Xie S, Rohrbach M, et al. Decoupling representation and classifier for long-tailed recognition[J]. arXiv preprint arXiv:1910.09217, 2019.
[4] Cui Y, Jia M, Lin T Y, et al. Class-balanced loss based on effective number of samples[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 9268-9277.
[5] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2980-2988.