YOLOv2 学习笔记
0. 前言
本文是看b站同济子豪兄的视频【精读AI论文】YOLO V2目标检测算法的笔记。强烈推荐同济子豪兄的各种视频,讲得详细准确又生动。本文中的部分插图来自原文[2],也非常建议阅读一下原文。
1.Better
相对于YOLOv1增加的了:

1.1 Batch Normalization
Batch Normalization做了啥:

具体的算法流程(来自论文[1]):

Batch Normalization的目的:使得数据分布在0附近(以0为均值,以1为标准差的分布),从而使数据落在激活函数(如双曲正切函数、sigmoid函数)的非饱和区。如下图所示:
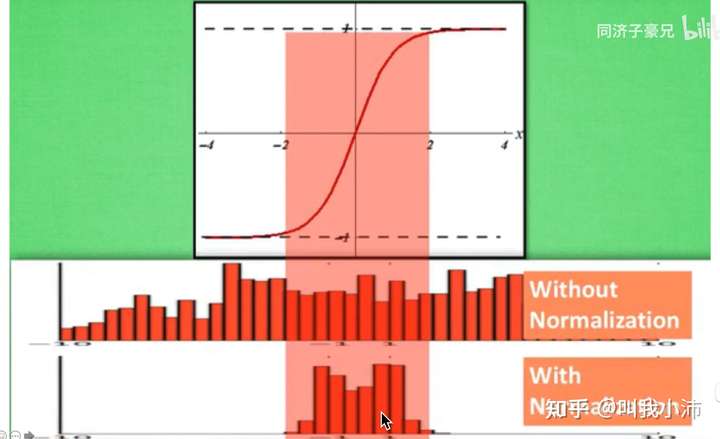
Batch Normalization的好处(来自斯坦福CS231N课程):

1.2 High Resolution Classifier
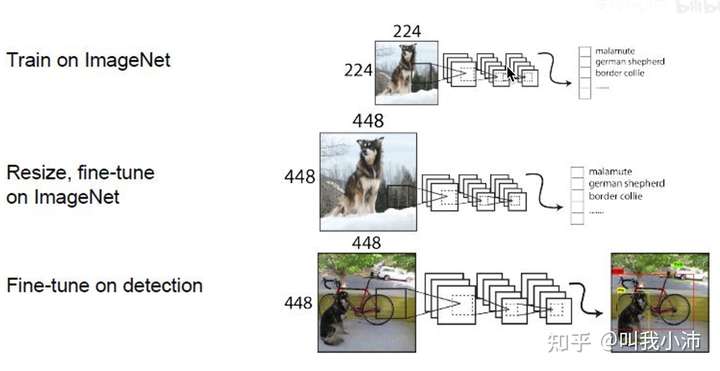
由于目标检测的数据集中图片大小是448x448,而ImageNet数据集的尺寸大小是224x224。用224x224的图片训练出来的骨干网络直接用到448x448的图片上是不合理的。因此先用224x224的图片训练一段时间,之后将其resize到448x448,再fine-tune 10个epoch,然后再进行目标检测训练。
1.3 Anchor
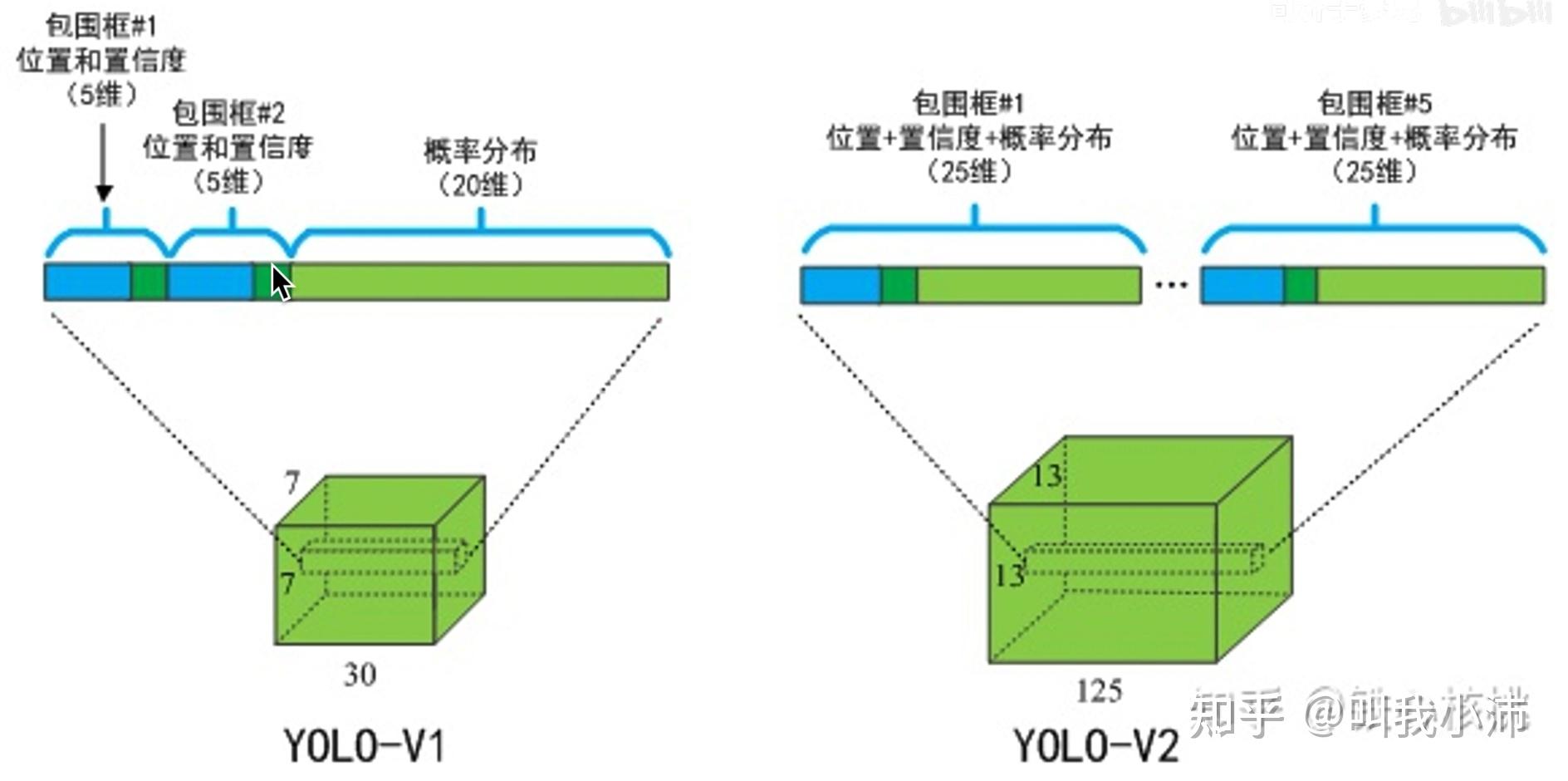
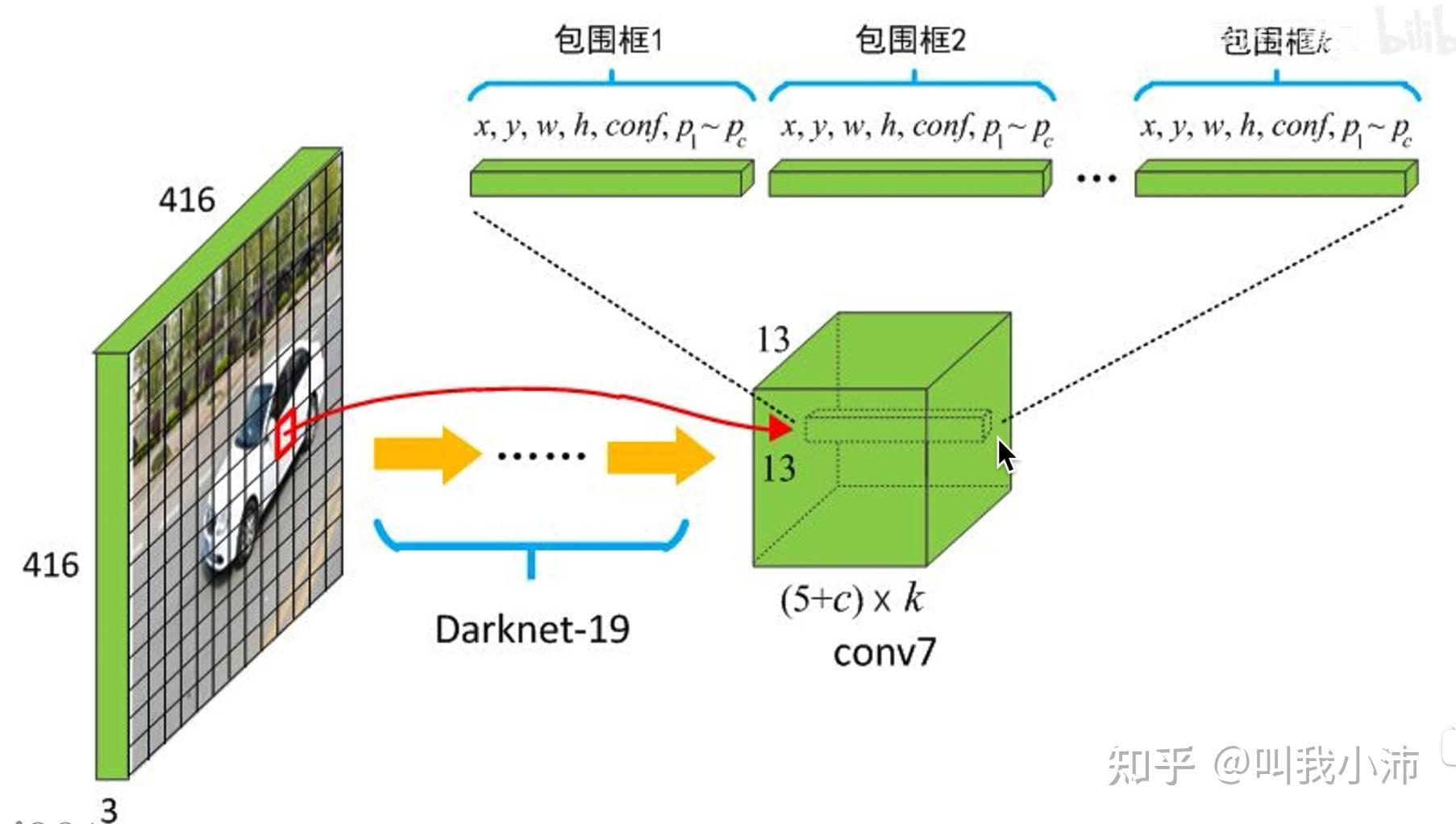
YOLOv2加入了锚框。事先指定了5种不同长宽、大小、尺度的先验框。首先将图片划分为13x13的grid cell,然后边界框(Ground Truth)的中心点落在哪个grid cell,就由哪个grid cell生成的5个Anchor种的一个进行预测。5个中的哪一个呢?和边界框的IOU最大的那一个。然后输出这个先验框相对于边界框的偏移量就可以了。

一个小技巧:在YOLOv2中把模型输出的feature map的长宽设置成了奇数。因为奇数的长宽有一个中心的grid cell,这样当目标位于图片的中心时(事实上很多图片的目标都在图片中心位置),就能以中心的一个grid cell进行预测;而当feature map为偶数时,需要4个grid cell进行预测,这样很不优雅。

这样一来,YOLOv2的的输出就变成了:
YOLOv2整体的输入输出:
YOLOv2预设的5个长宽、大小、尺度的先验框是通过对数据集中的边界框聚类得到的。使用k-means聚类算法,左边是聚类数量k和平均IOU之间的关系,考虑到准确度和模型复杂度之间的权衡,选择k=5. 右边是在VOC和COCO数据集上的5个先验框的可视化结果。COCO数据集有更大的尺寸变化。
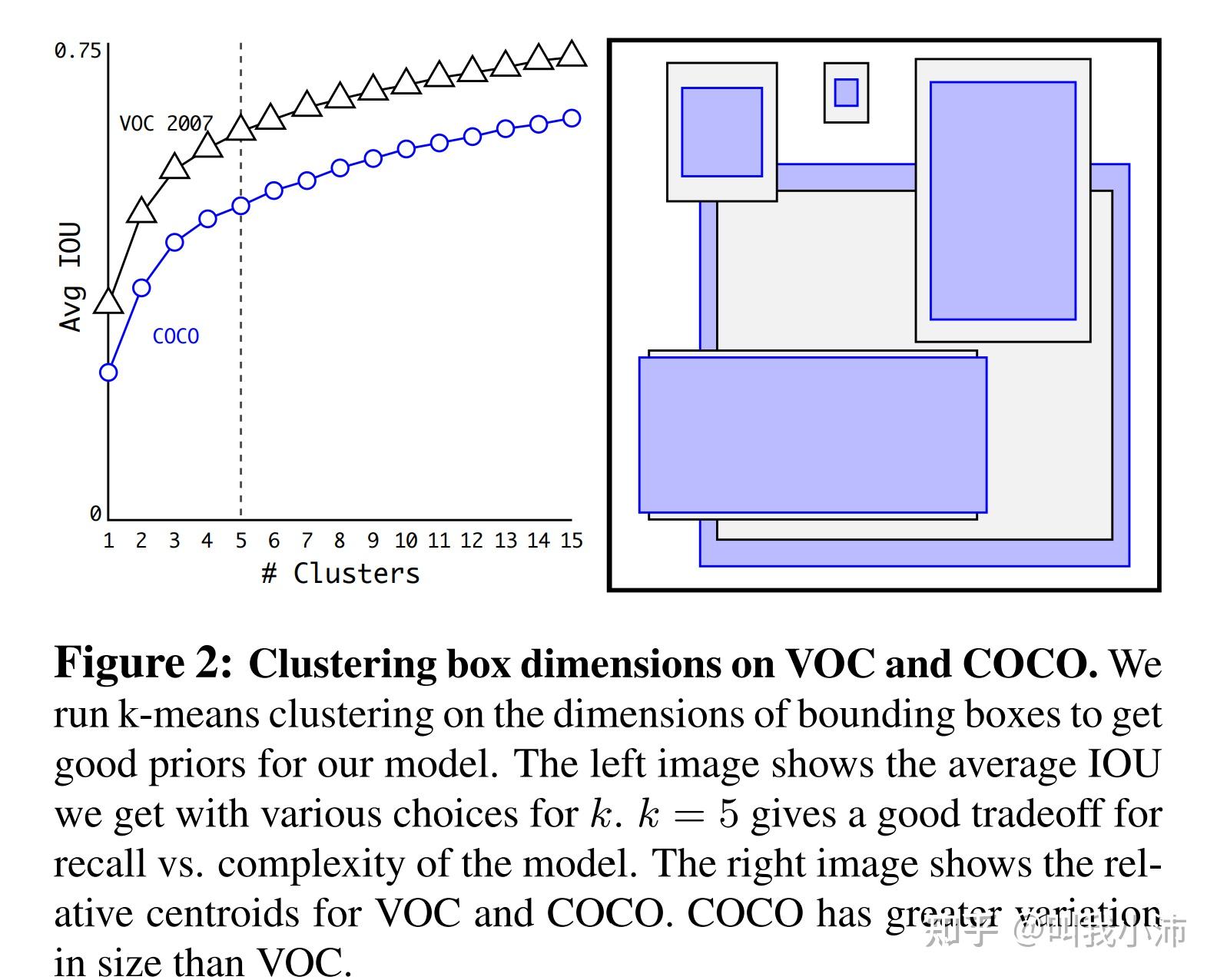
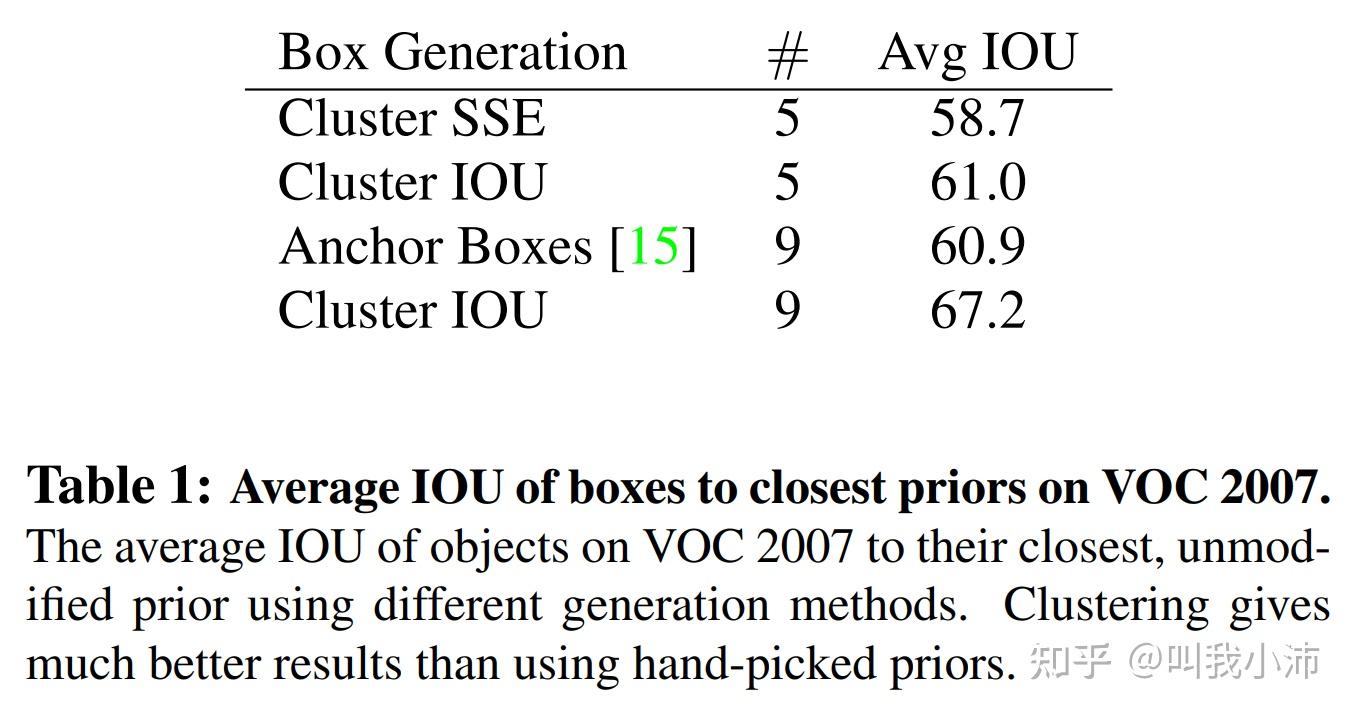
通过聚类的方法和手工选Anchor的方法得到的候选框的平均IOU结果如下,可以看出聚类的方法得到的结果要比手工好得多。(SSE:欧氏距离;Anchor Boxes:手工选取Anchor)
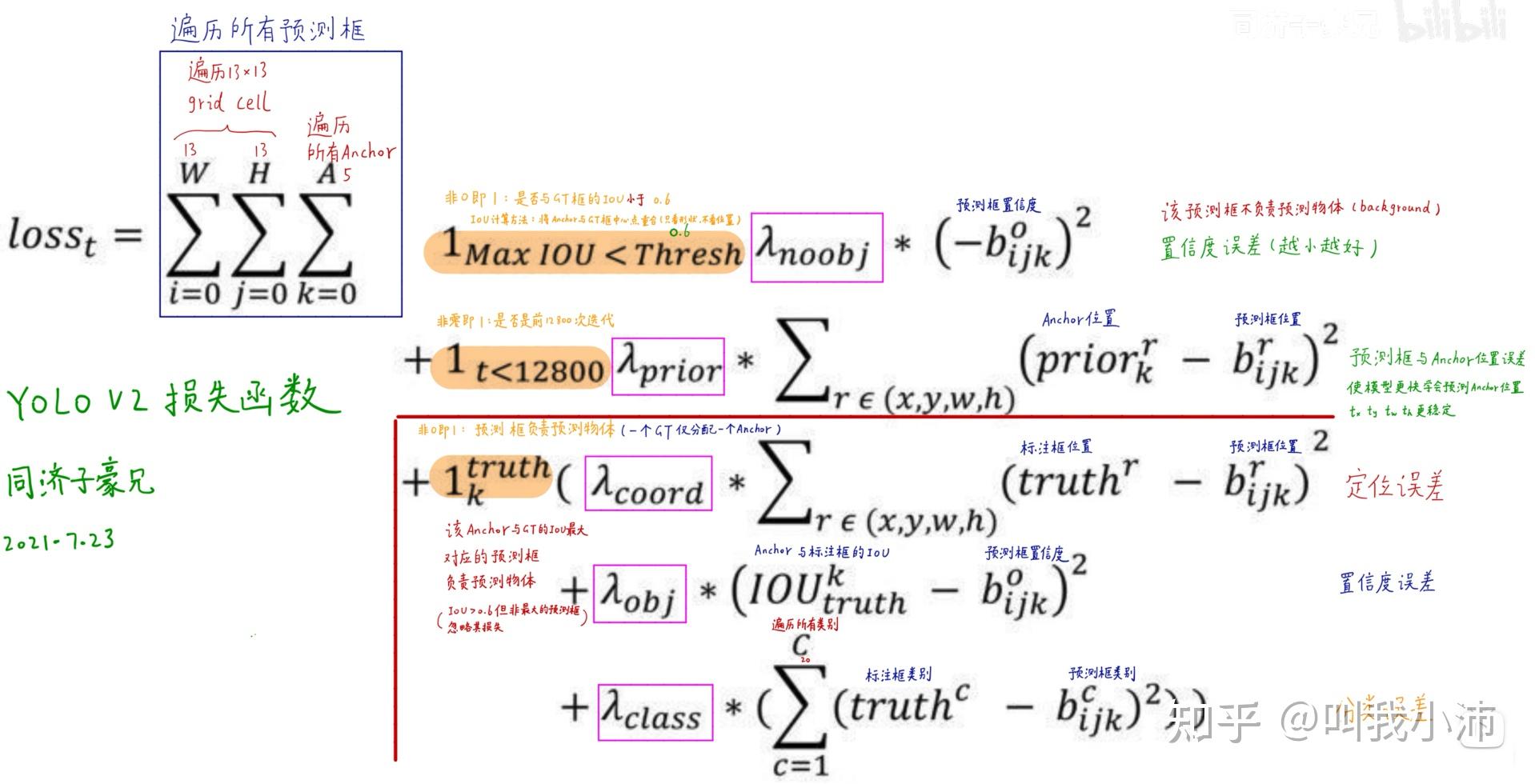
YOLOv2的损失函数:
1.4 Direct location prediction
通过$\sigma(t_x)$函数(即:sigmoid函数)限制预测框的中心点全图乱窜。$b_x, b_y, b_w, b_h$是预测框中心点和宽高的偏移量。$t_x, t_y, t_w, t_h, t_o$是预测出来的5个值,通过下面的公式来由这5个值计算出中心点和宽高的偏移量,以及预测框的置信度。$c_x, c_y$是预测框所在grid cell的左上角相对于全图左上角的位置。$p_w, p_h$是anchor的宽高。
这里说明一下anchor(锚框,也称先验框)和预测框的区别:
(1)anchor是在模型训练之前就生成了的5个先验框,从这5个先验框中,选取一个和Ground Truth的IOU最大的框用来预测物体;
(2)我们拿着模型预测出来的4个值($t_x, t_y, t_w, t_h$),计算出来4个偏移量($b_x, b_y, b_w, b_h$),然后在上面选出的那个先验框的基础上进行偏移所得到的框就叫做预测框。
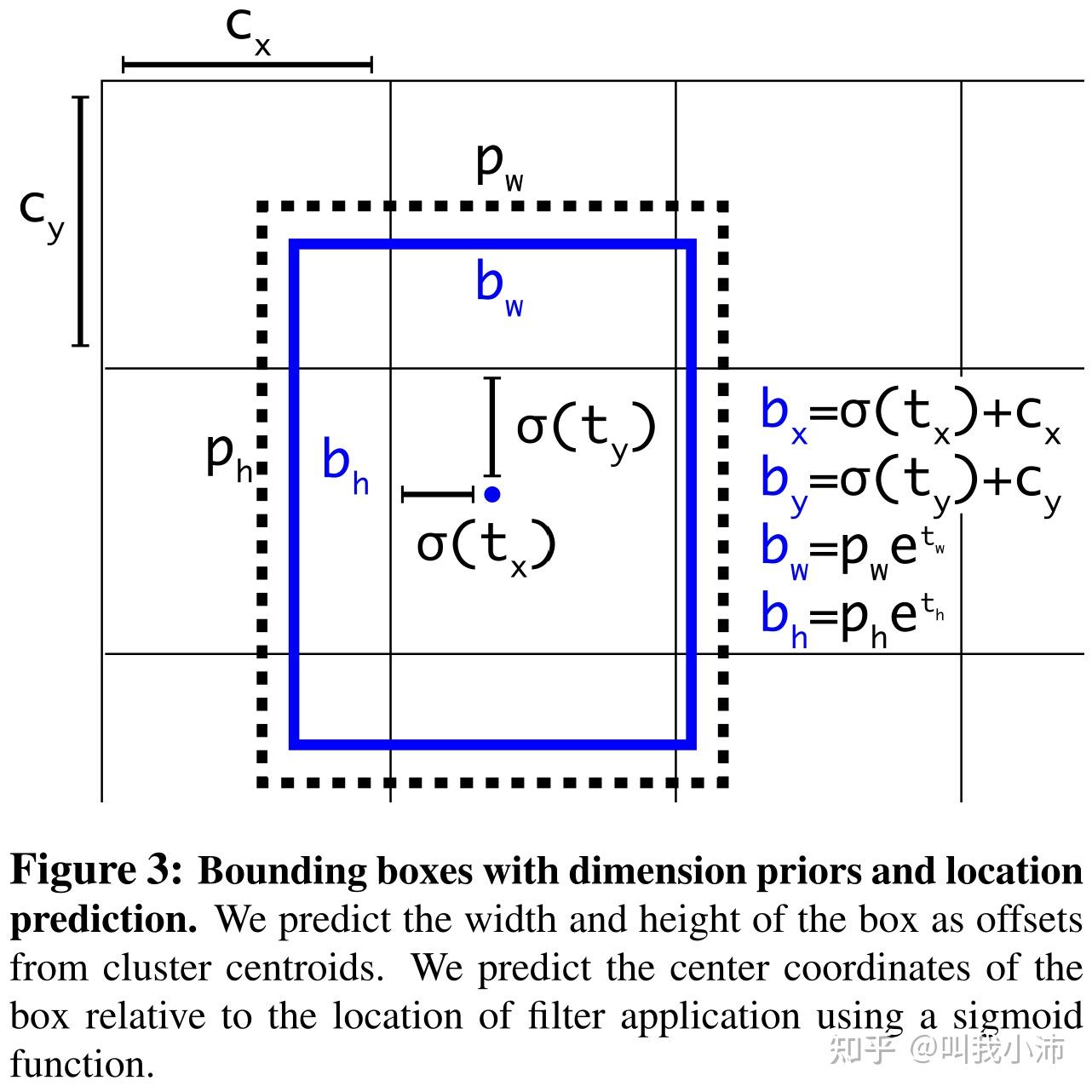
下面公式中$Pr(object)$是预测框的置信度。
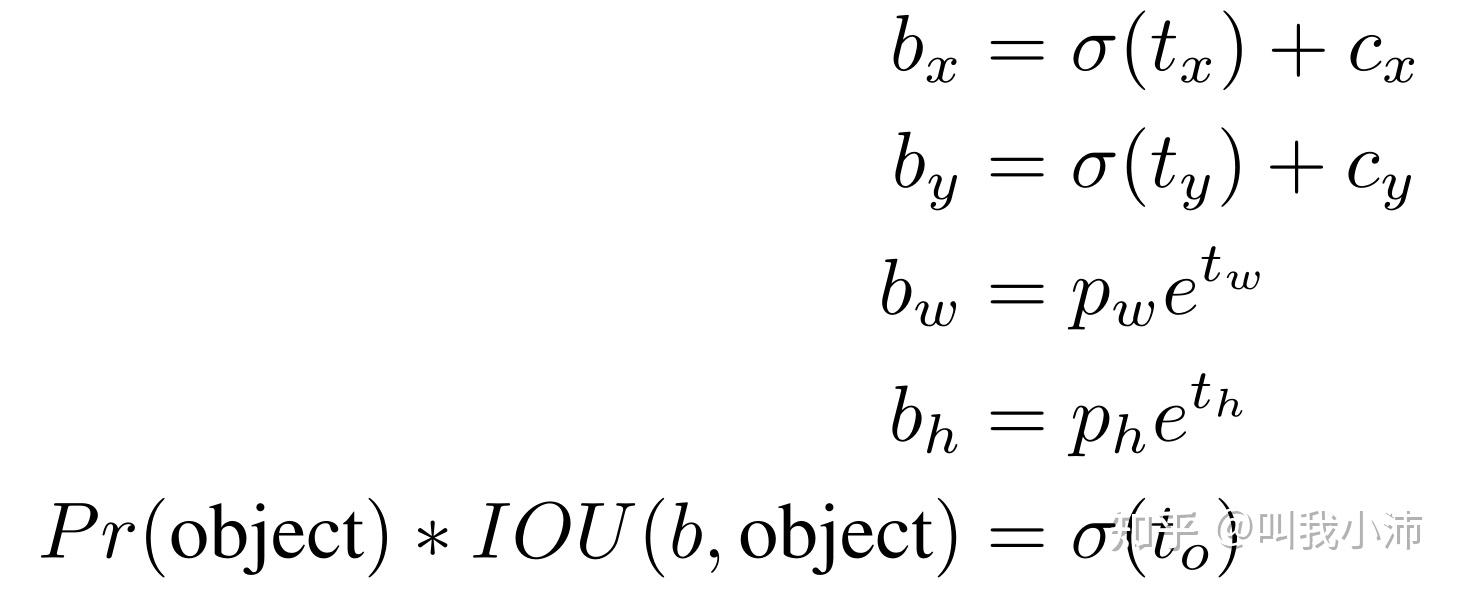
1.5 Fine-Grained Features (细粒度特征)
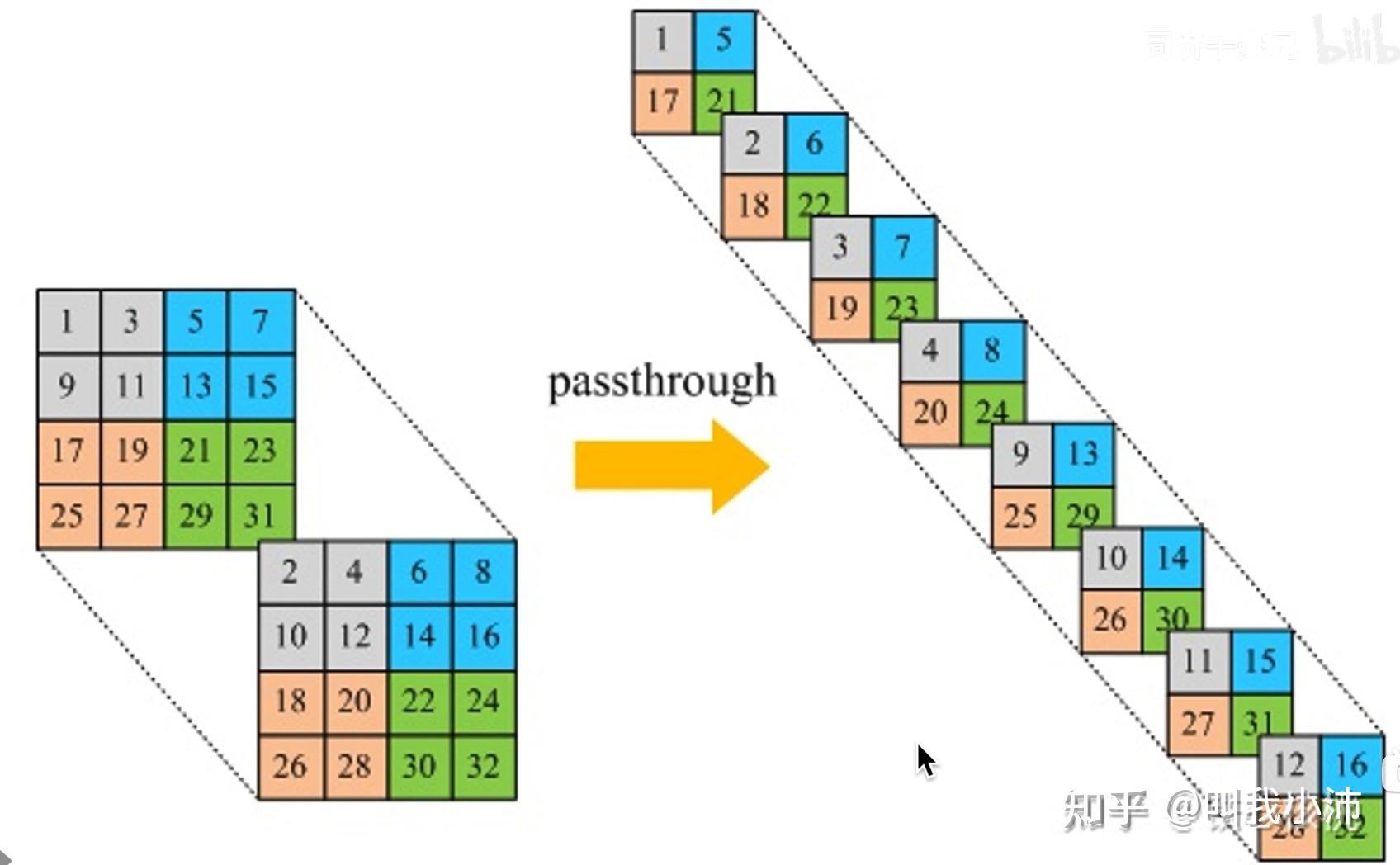
在最后pooling之前,把特征图分成两路处理:一路进行正常的conv+pooling操作,减小特征图尺寸,增加通道数;另一路将原特征图拆分成四份,在通道维拼接成一个长条(称为passthrough层);最后再将两路特征拼接在一起。这样能够保留较低层的特征(有点DenseNet的味道)。
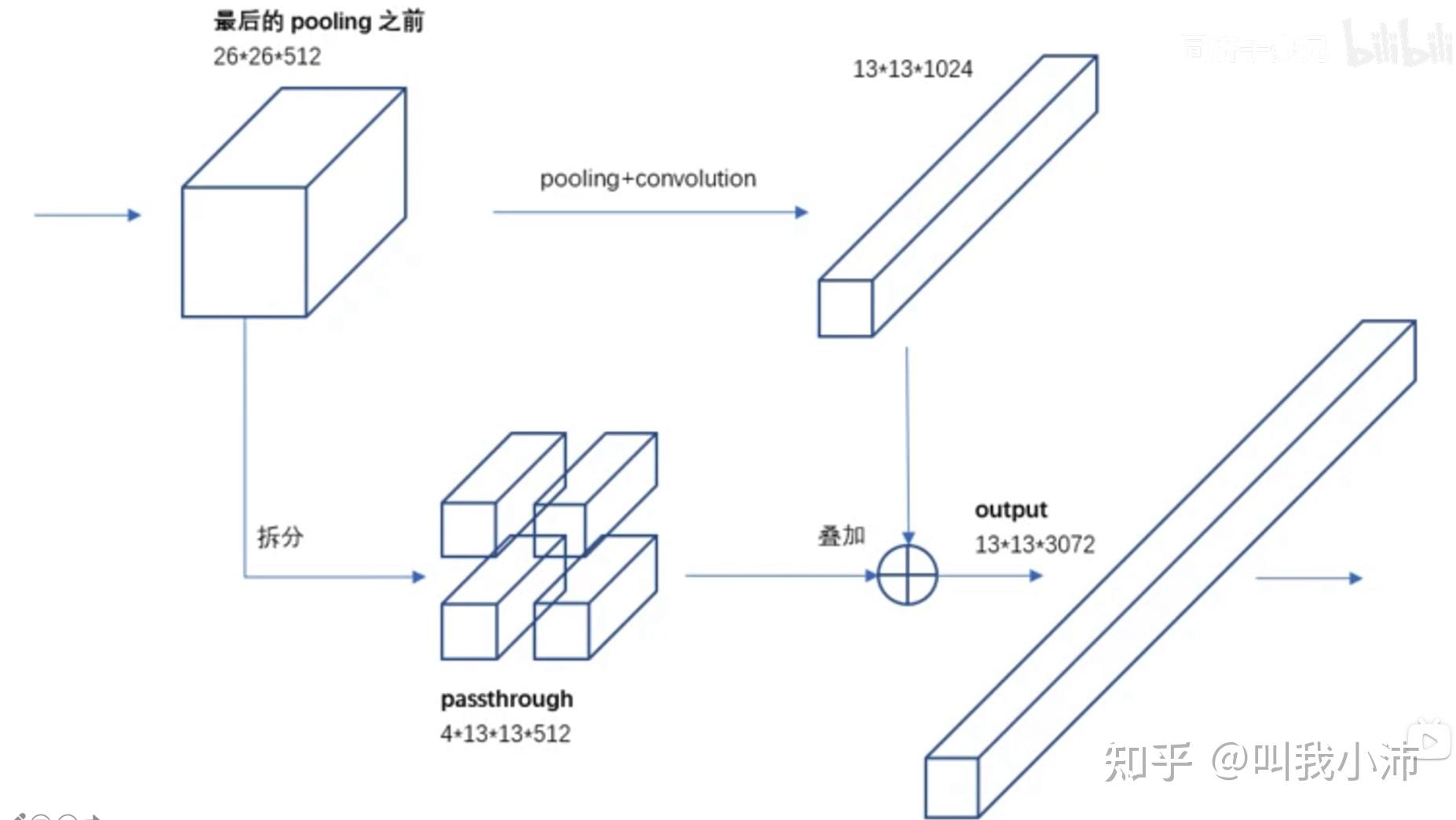
passthrough层 的另一种理解方式:
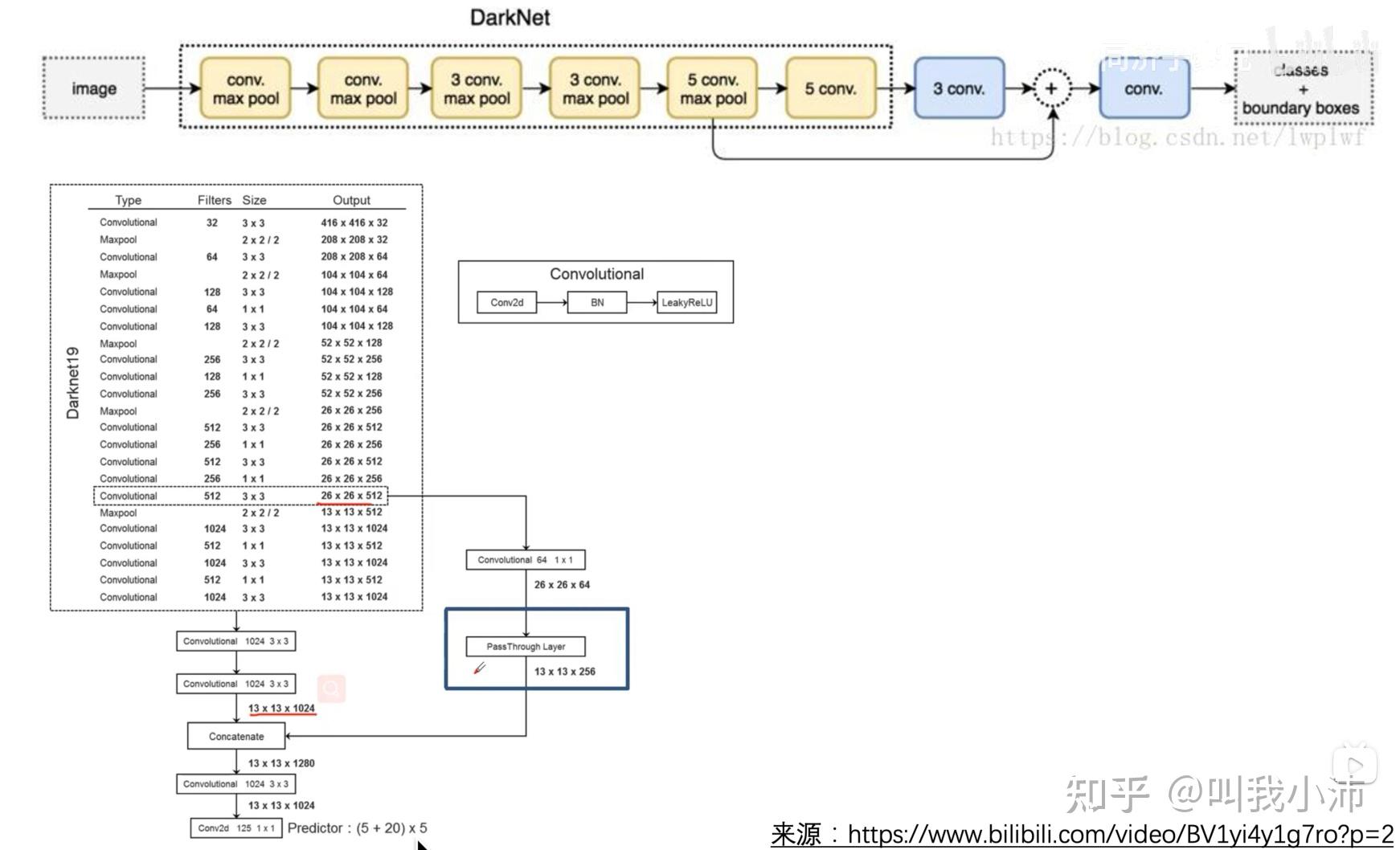
放在整个网络中进行理解:
1.6 Multi-scale training (+1.5% mAP)
同一个模型,每10步就选取一个新的输入图像大小,以使得模型能够适应不同大小的图像输入。为什么可以这样做呢?这是因为使用了Global Average Pooling (全局平均池化,GAP)操作。虽然模型最后输出的feature map大小不同了,但是使用了GAP之后,不同尺度的feature map都变成了相同的大小(即:1)。
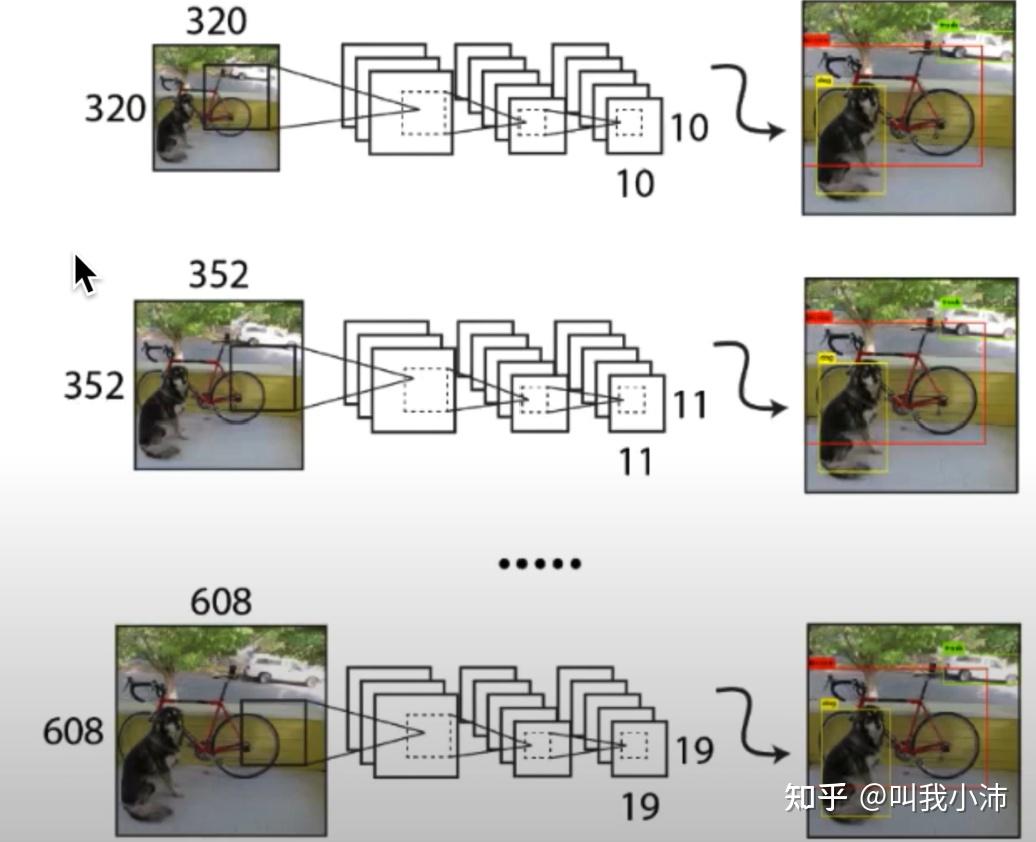
这个操作还有一个副作用:如果输入的是一张大图片,模型会预测得比较慢,但是很准;如果输入的是一张小图片,模型会预测得比较快,但是不太准。因此可以通过选择不同尺寸的输入来进行“精度-速度”的权衡。
论文中得到的输入不同尺寸图片下的结果:
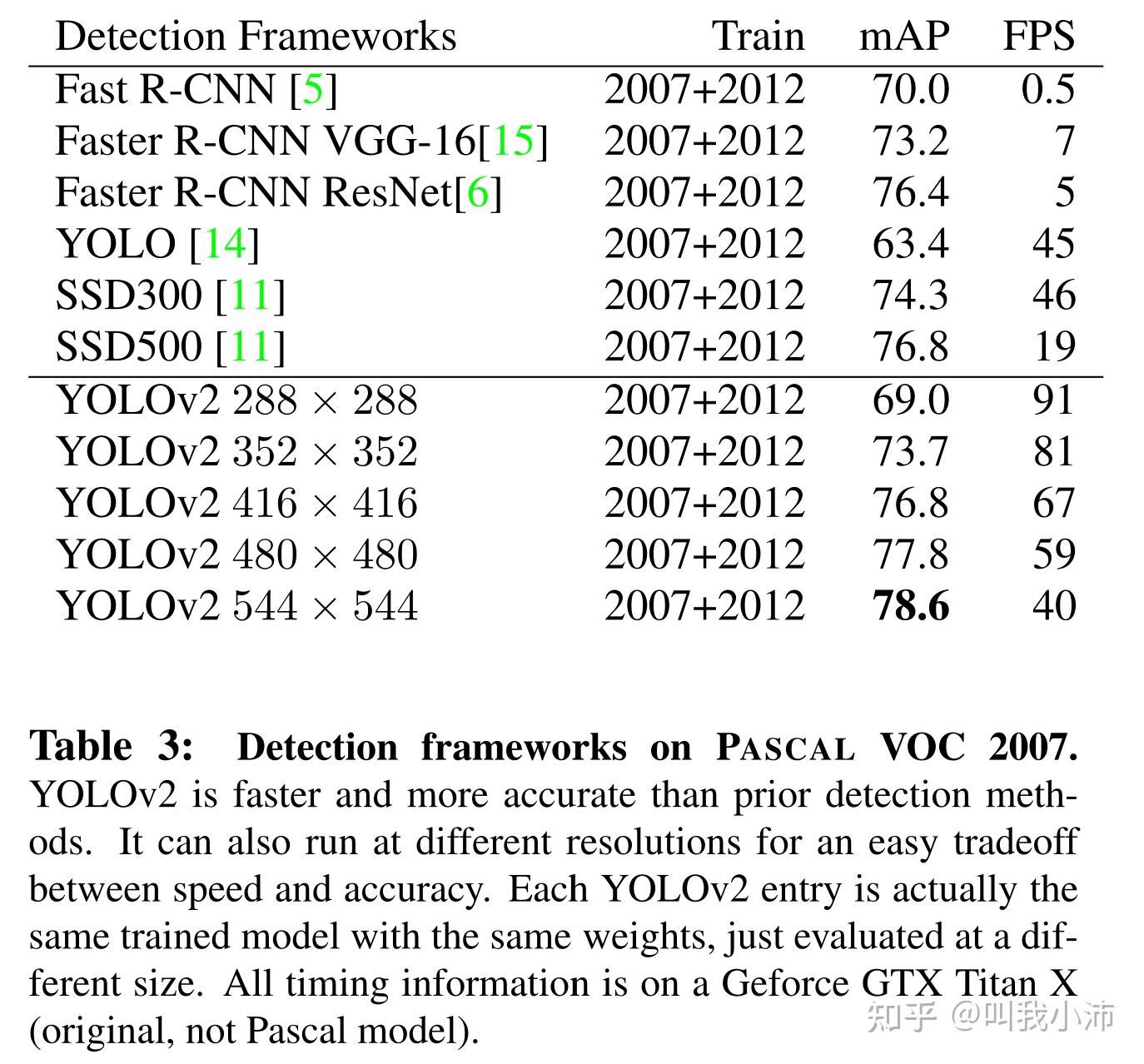
1.7 Better部分小结
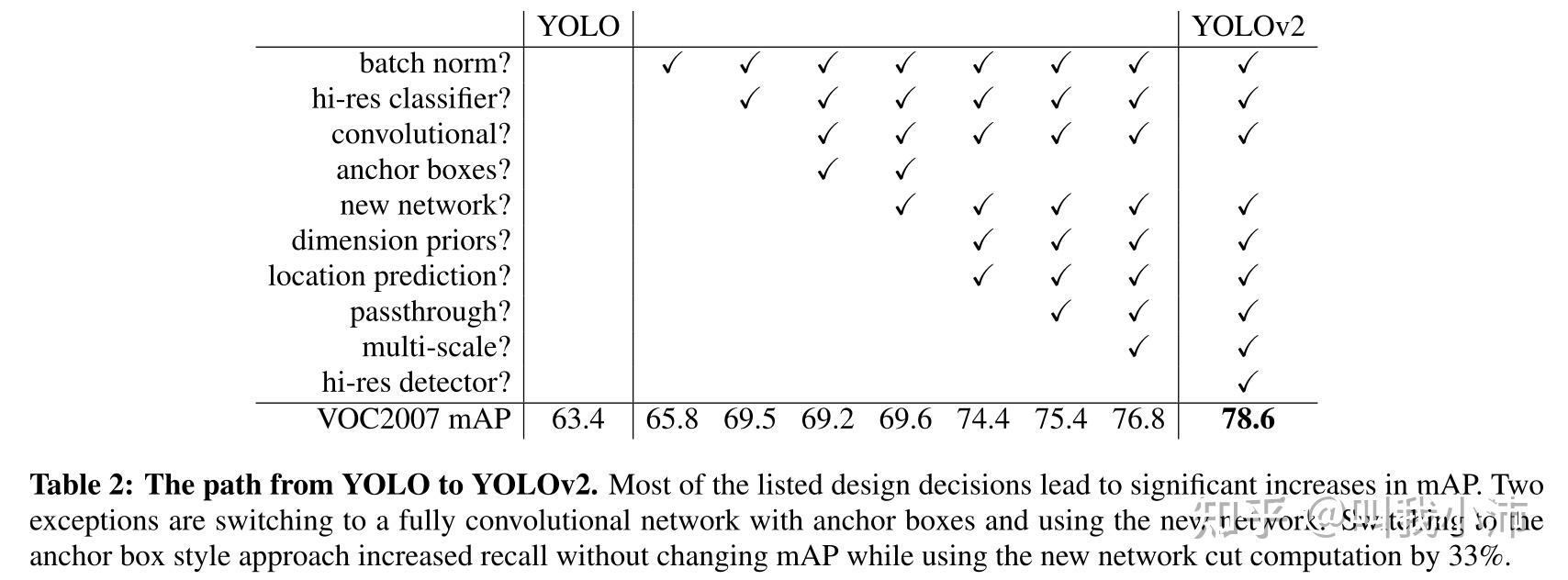
YOLOv1 演变到 YOLOv2 的过程。从表中可以看出,加了Anchor boxes之后mAP反而下降了,为什么还要采用呢?因为加了Anchor之后可以大大增加Recall,所以是值得的;另外换了new network之后也没有很大的提升,那为什么要换呢?这是因为DarkNet相对于YOLOv1的骨干网络可以大大降低计算量,所以也是值得的。
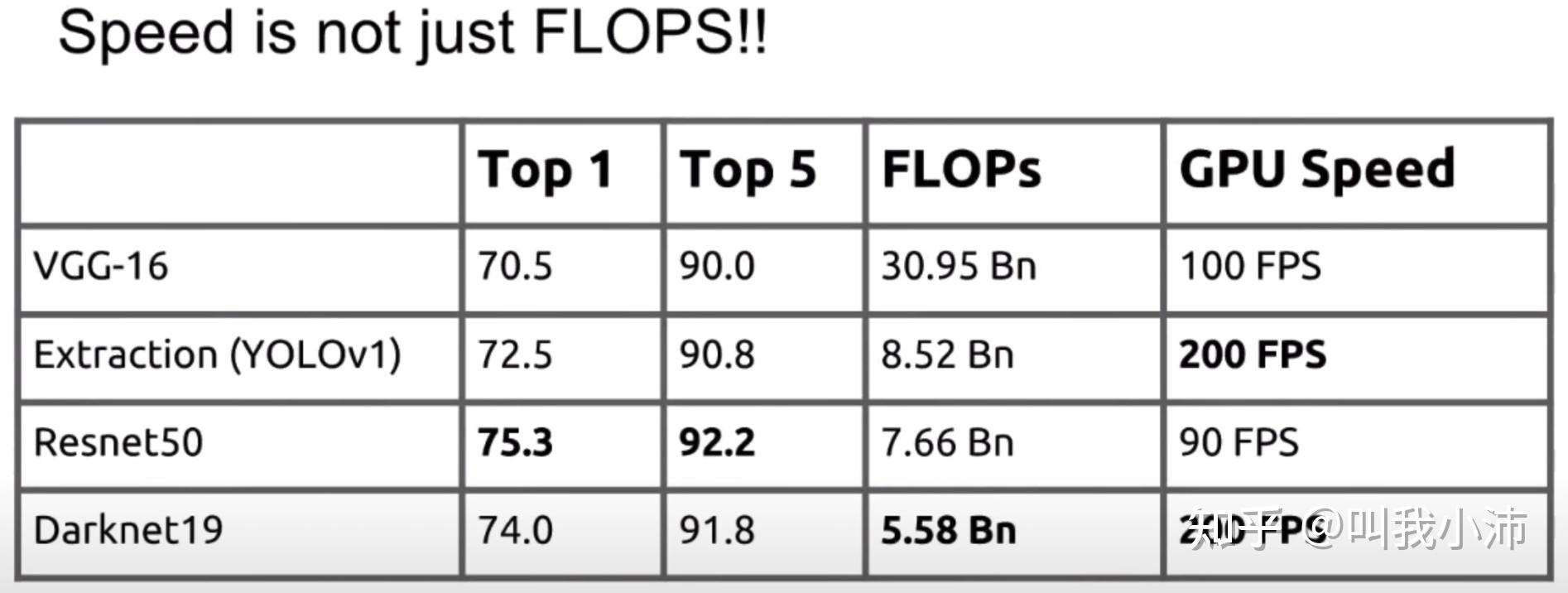
2. Faster
YOLOv2变更快的主要原因是换了新的骨干网络。下面是使用不同的骨干网络的速度、精度对比。
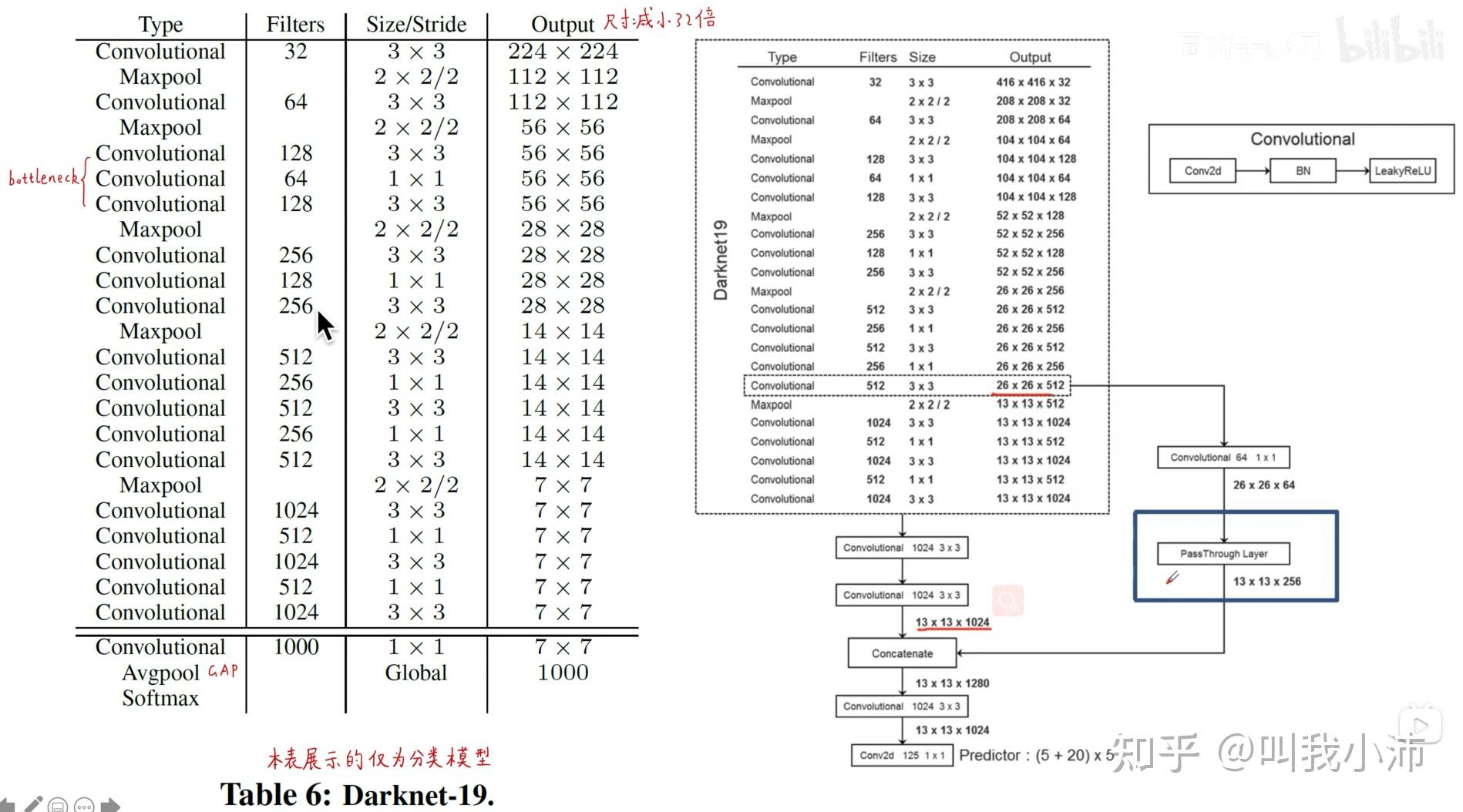
Darknet19网络结构如下,左边是分类的网络,右边是检测的网络。
3. Stronger(类别更多)
这个技巧并没有在后面的论文中用的特别多,但可以作为一个开脑洞的想法来了解一下。
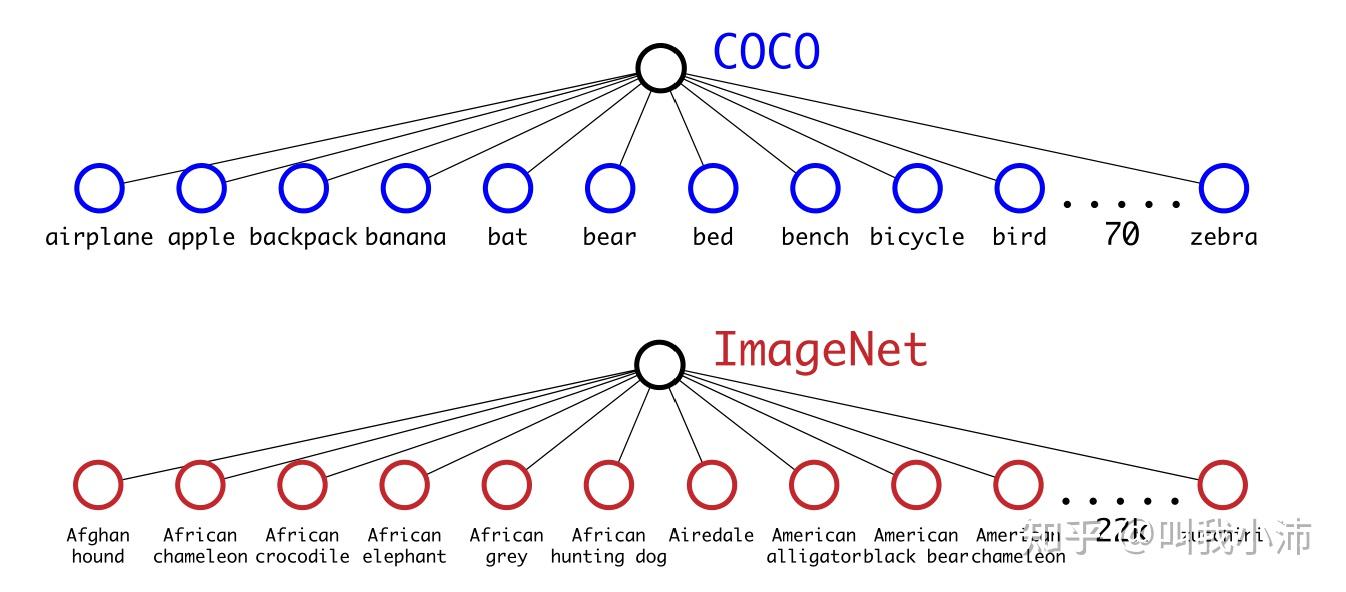
COCO里面只有80个类别,而ImageNet里有22k个类别。因此,作者考虑将COCO数据集和ImageNet数据集结合起来训练YOLOv2,让模型既进行分类的训练又进行目标检测的训练,使得模型能进行细粒度的目标检测,能够检测出更多类别的物体。
但是强行将这两个数据集结合起来是很困难的。例如在ImageNet中美洲黑熊和亚洲黑熊是两个不同的类别,这是更细粒度的标签;而在COCO数据集中只有黑熊这一种相对来说粗粒度的标签。那么怎么将这两个数据集结合起来呢?

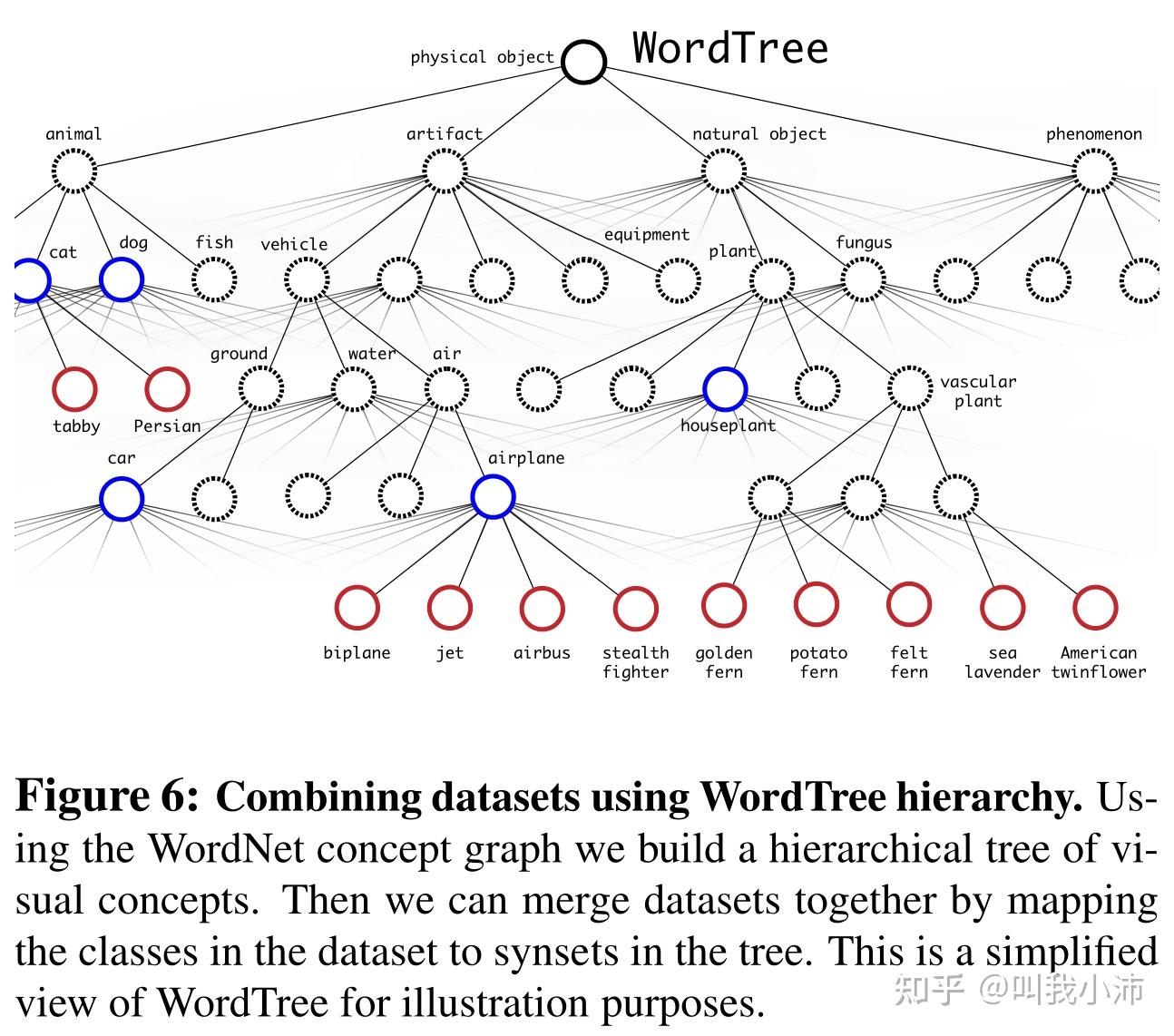
在YOLOv2中采用了将分类标签变成树状结构的方法,逐层使用softmax进行分类,这样就能将粗粒度的COCO和细粒度的ImageNet放在一起训练了。
下面是树状标签结构和逐层softmax分类的另一种表示方法。
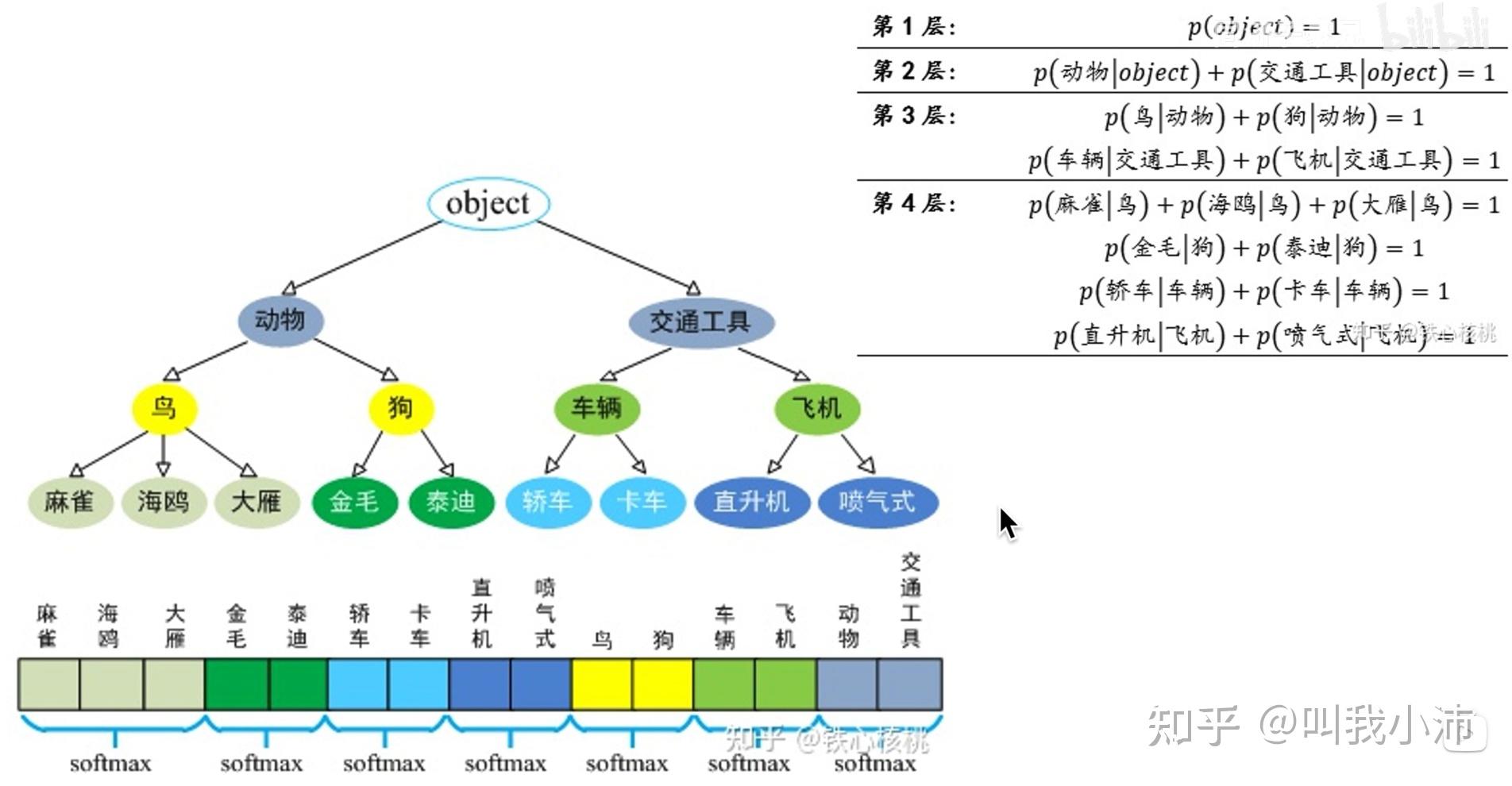
从而要计算一个节点的绝对概率,就可以通过计算其一系列父节点的条件概率的乘积。例如要计算一张图片是卡车的概率,就可以这样计算:
$$
P(卡车) = P(交通工具|object) * P(车辆|交通工具) * P(卡车|车辆)
$$
在论文中也给出了一个计算一张图片是否是Norfolk terrier类别的例子:

在训练过程中,如果输入一张目标检测的图片,就反向传播目标检测的误差;如果输入的是一张分类的图片,就反向传播分类的误差。这样就可以让模型既学习到目标检测画框框的能力,又学习了ImageNet海量数据细粒度分类的能力。
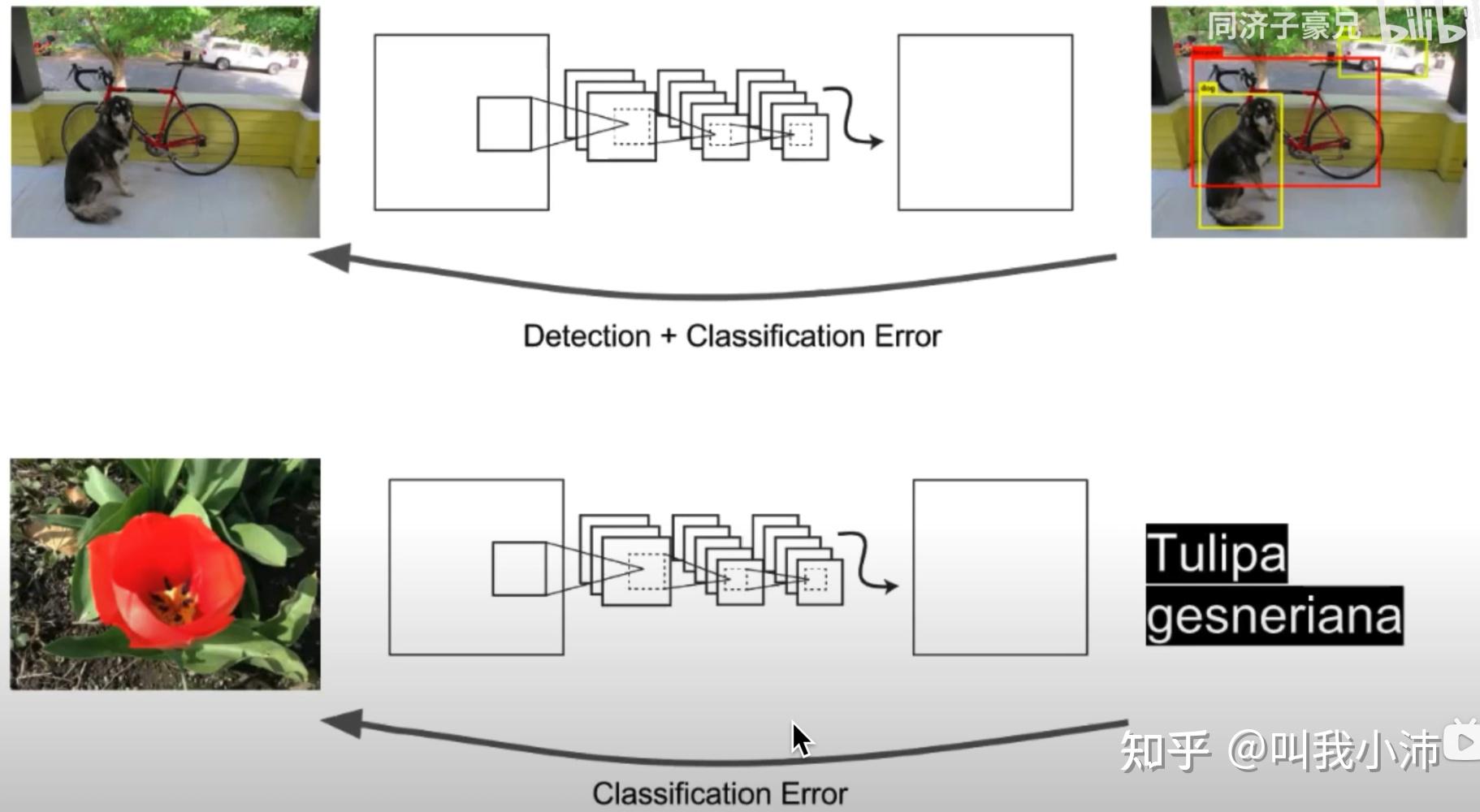
作者在COCO数据集和ImageNet分类数据集中进行了联合训练,在ImageNet目标检测数据集中进行了测试,得到的结果如下。从结果中发现,这样训练得到的动物的准确率是不错的,但是衣服和装备这些类别的效果是不好的。

[1] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//International conference on machine learning. PMLR, 2015: 448-456.
[2] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7263-7271.
另外附上同济子豪兄视频中的推荐观看: