本文系统总结了用于长尾识别的各种trick,实验得出了不同trick组合会带来不同的效果,给出了详细的实验指南;并提出了一种新的基于CAM的DRS采样方法;通过本文的trick组合,在CIFAR-LT、iNaturalist、ImageNet-LT上得到了最好的结果。
5.1 Trick有哪些?
本文把长尾识别的trick分为了四个类别,包括:
1.Re-weighting
现有的re-weighting方法:
代价敏感softmax交叉熵损失(CS_CE)
该损失在普通的交叉熵损失函数(CE)前乘上了最小类别中的训练图像数与每个类别的图像数的比值。相当于减少了多数类别的损失贡献,增加了少数类别的损失贡献。
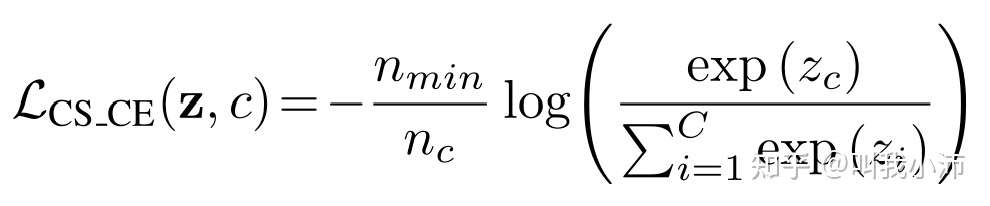
Focal loss
focal loss可以通过设置参数$\alpha$和$\gamma$的来控制少数类别、难分类类别对损失的贡献。
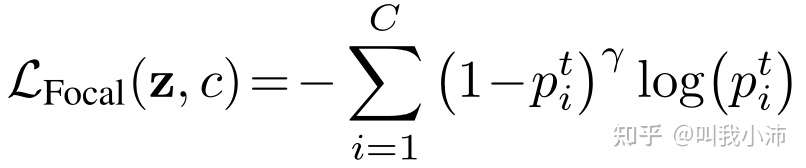
类别平衡损失
类别平衡损失这篇文章提出了一个“样本体积”的概念,其核心思想在于:数据集中的样本并不是都能提供有效的信息,因此应该以类别中的有效类别数量对loss进行加权(而不是直接使用样本数量对loss进行加权)。
具体来说,就是在普通的损失(如CE、Focal等)前加上一个$\frac{1-\beta}{1-\beta^{n_c}}$项,其中$\beta$是一个超参数。
CB_Focal
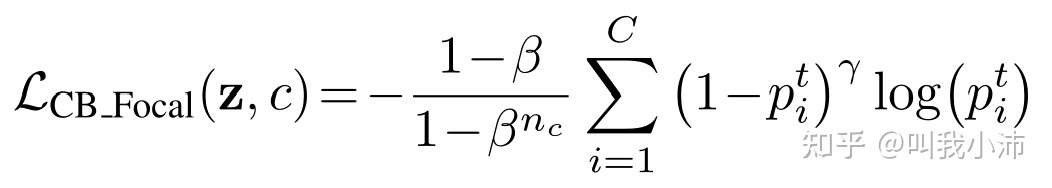
CB_CE
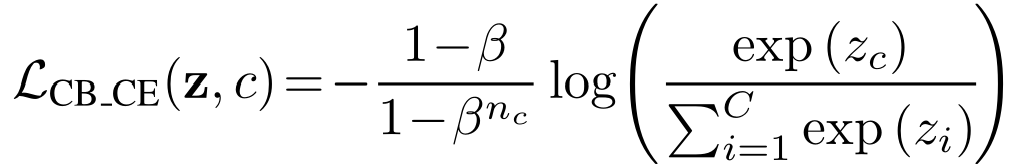
对re-weighting方法进行实验:
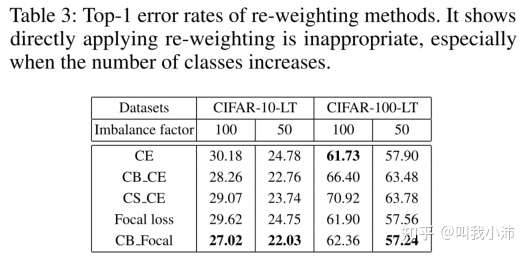
可以从实验结果看出,增加图片类别之后一些re-weighting的方法反而不如普通CE好了。
2.Re-sampling
现有的re-sampling方法:
随机过采样
通过随机重复采样少数类别样本来构建平衡的数据集;
随机降采样
通过随机删除多数类别的样本来构建平衡的数据集;
类别平衡采样
首先对类别进行统一采样,即每个类别被采样的概率都一样(下式中$q=0$的情况);然后从每个类别中有放回地随机采样实例,从而构建一个平衡的数据集;
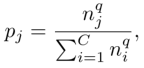
该式中$p_j$表示从数据集中随机采样一个样本,其来自类别$j$的概率。
平方根采样
上式中$q=1/2$的情况。
逐步平衡采样
先对多个epochs进行实例平衡采样(上式q=1,也就是没有任何平衡操作的采样),然后在剩下的epochs中进行类别平衡采样。这种采样方法需要设置一个超参数来调整从哪一个epoch开始变换采样方式。也可以使用更软的阈值,即随着epoch的增加逐渐调整实例平衡采样(IB)和类别平衡采样(CB)所占的比例,如下面公式所示。
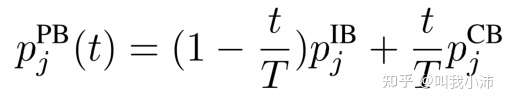
对re-sampling方法进行实验:
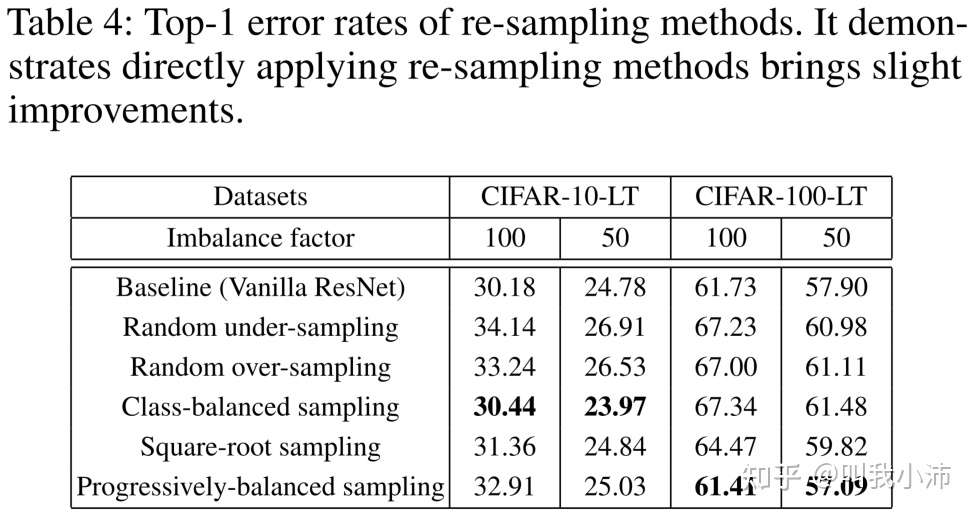
从实验结果可以看出,直接将重采样用于训练过程得到了轻微的改进.
3.Mix-up training
现有的mixup方法:
Input mixup(输入混合)
通过下式对训练样本进行数据增强。其中$(x_i,y_i)、(x_j,y_j)$是随机采样的两个样本,$\lambda$是一个从beta分布中随机采样得到的0到1之间的数值。在训练时使用$(\hat{x},\hat{y})$作为输入。
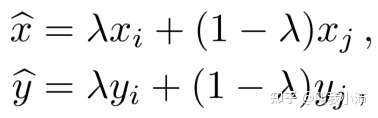
Manifold mixup(流形混合)
首先将随机采样的两个样本$(x_i,y_i)、(x_j,y_j)$输入网络,在网络的第$k$层得到输出$(g_k(x_i),y_i)、(g_k(x_j),y_j)$,随后通过下式对两个训练样本的中间输出进行混合,$\lambda$是一个从beta分布中随机采样得到的0到1之间的数值。在训练时使用$(\hat{g_k},\hat{y})$作为输入。在本文中只是使用了一层网络进行manifold mixup。
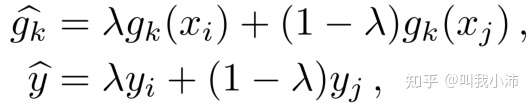
在mixup 训练后进行fine-tuning:
前人已经证明在mixup训练的后面几个epochs去掉mixup,所得的结果会有明显的提升[3]。在本文中,为获得进一步提升,先使用mixup训练,然后用源数据集对mixup训练后的模型进行了微调。
对mixup training方法进行实验:
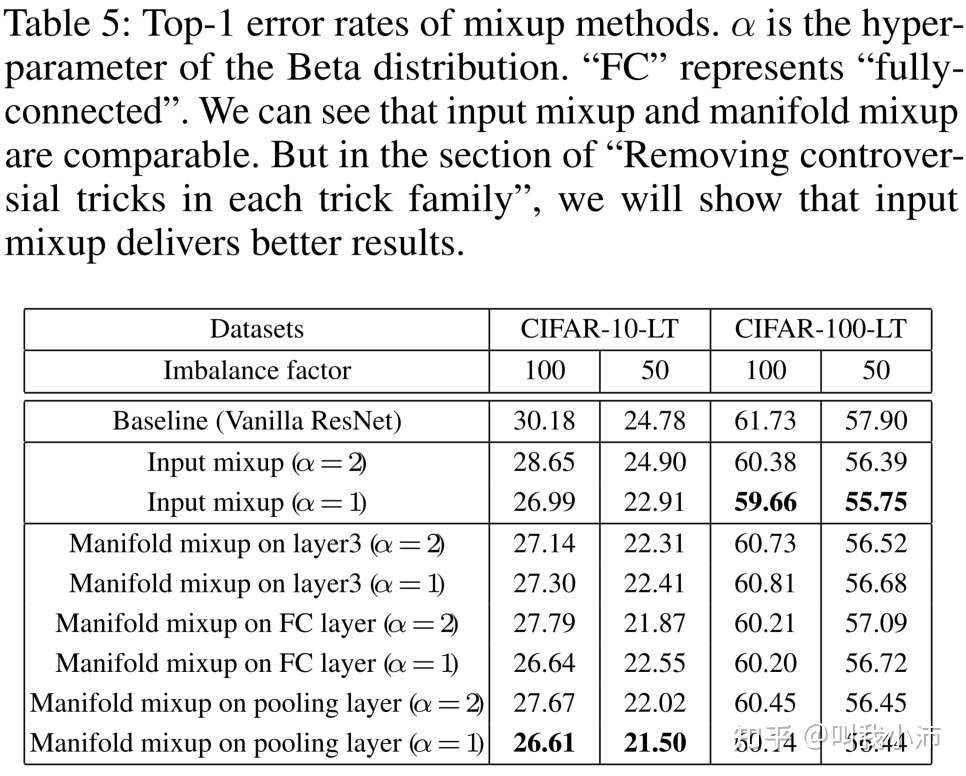
从表中可以看出Input mixup和Manifold mixup的方法相对于baseline都有一定的提升;当设置$\alpha=1$且混合位置设置为pooling layer时Input mixup和Manifold mixup的结果相当。
对“先mixup 训练、再进行fine-tuning”的方法进行实验:
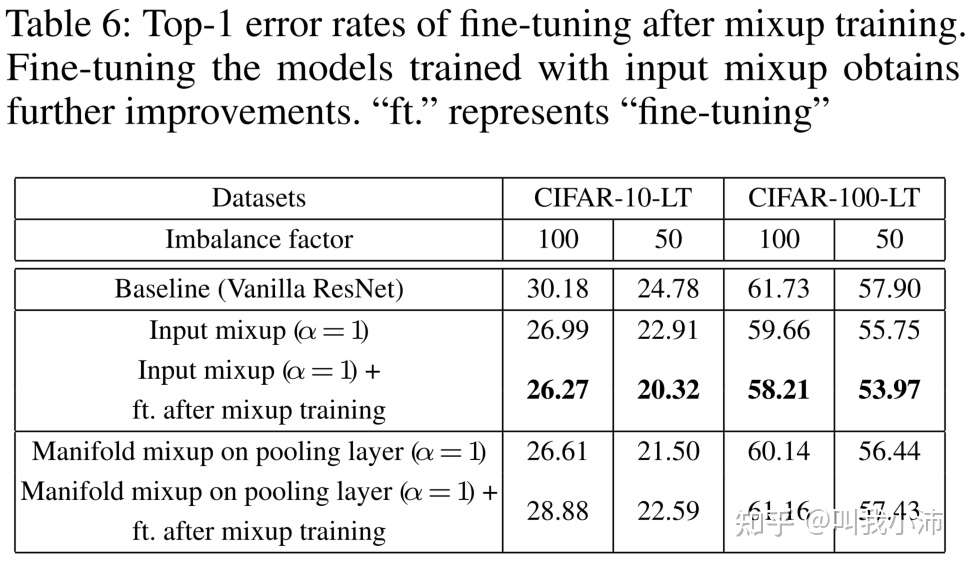
从表中可以看出Input mixup训练后进行微调可以得到进一步的提升,但Manifold mixup训练后进行微调效果反而变差了。
4.Two-stage training
在不平衡训练后进行平衡微调:
从长尾分布的数据集中模型可以学到高质量的特征表示,但是在尾部类中的识别准确率很低。现有的两阶段方法的两个阶段可以归纳为:首先在不平衡的数据集中对模型进行训练、然后使用重采样(DRS,实际上就是RS,论文中换了一种说法:延迟重采样,下同)或重加权(DRW)的方法对模型的分类器进行微调。
本文提出的基于CAM的DRS方法:
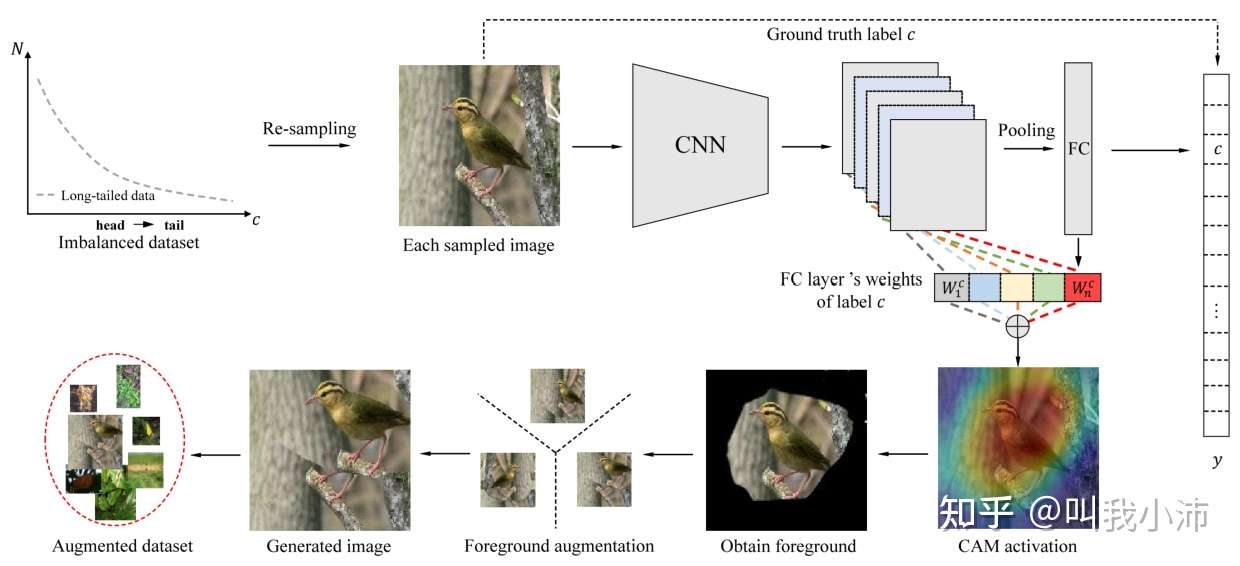
该方法首先对长尾分布数据集进行重采样得到平衡数据集,然后对于每张采样到的图片,使用在第一个训练阶段得到的参数化模型,根据其真实标签和相应地全连接层权重生成CAM(具体方法参考[4]),之后根据CAM地平均值对图片前景和背景进行分割,最后对前景进行变换(对每张图片随机选取“水平翻转、平移、旋转和缩放”中的一种进行变换),同时保持背景不变,生成新的图片作为训练集。
对于前面说的重采样方法,本文将CAM和现有的重采样方法(降采样、过采样、类别平衡采样、平方根采样、逐步平衡采样)进行了结合,命名为“CAM-based xx-sampling”。
对Two-stage training方法进行实验:
第二阶段采用重采样方法的实验结果:
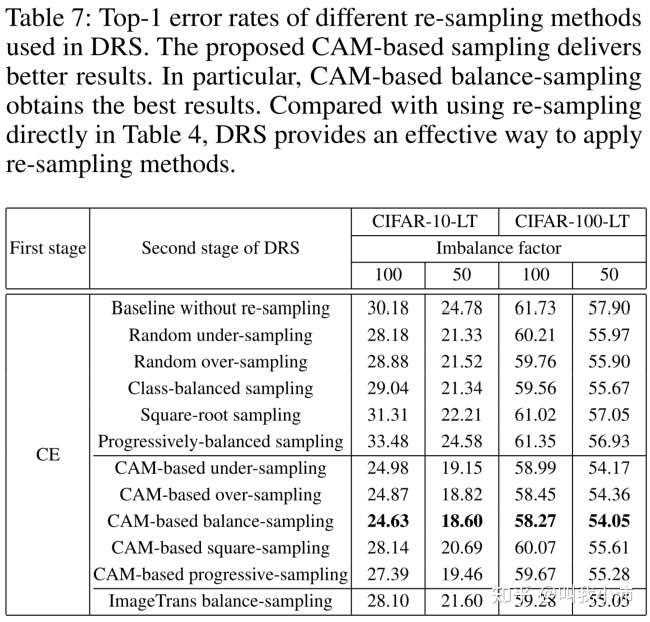
从表中可以得出:
1)两阶段(第二阶段重采样)的方法相比直接重采样的方法结果有所提升;
2)基于CAM的采样方法可以让结果更好;
3)基于CAM的类别平衡采样得到了最佳的结果;
4)加入了只进行图像变换(即水平翻转、平移、旋转或缩放)的方法作为对比,证明了CAM的有效性。(我觉得这个对比实验加的很不错,给读者一种实验很严谨、很充分的感觉)
第二阶段采用重加权方法的实验结果:
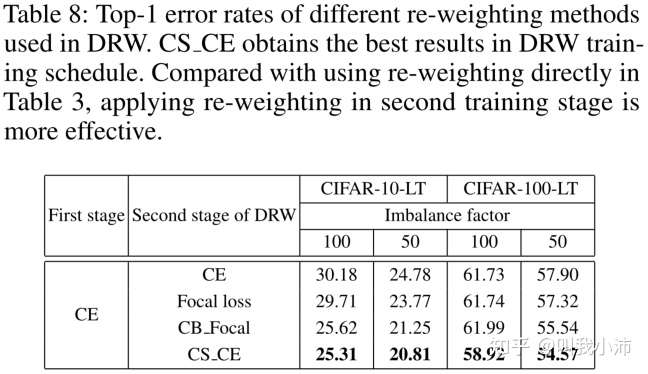
从表中可以看出,两阶段(第二阶段重加权)的方法相比直接重加权的方法结果有所提升,且CS_CE方法的效果最好。
5.2 Trick包
本文通过实验探索了怎么样组合Trick可以得到最佳的准确率,得到了如下的结果:
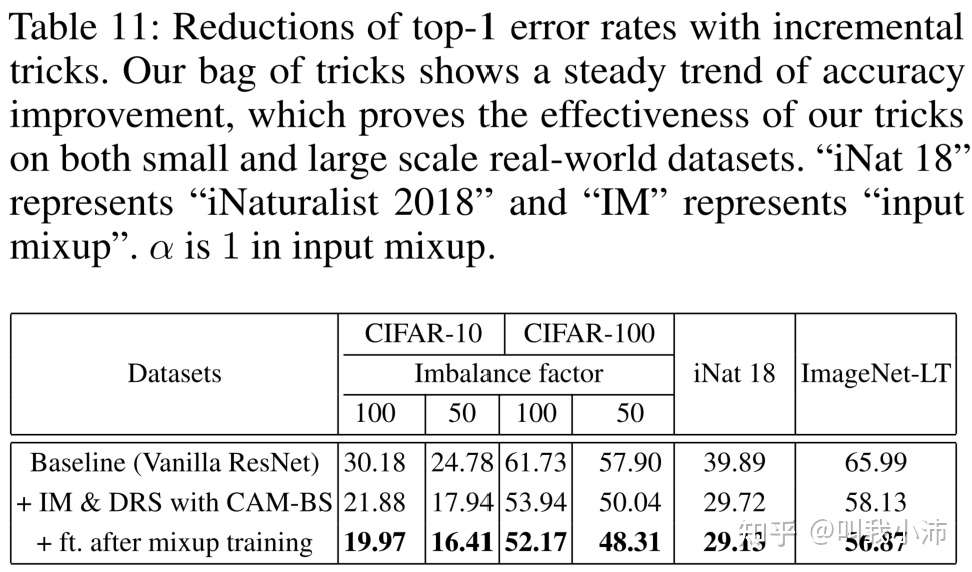
最终得出了最佳的Trick组合:输入混合(Input mixup)+用本文提出的基于CAM重采样方法进行两阶段训练+在mixup training之后进行微调。
我把它们按照训练时的顺序进行一个总结(我自己的理解):
第一阶段:用输入混合(Input mixup)方法对数据集进行增强,然后在开始的几个epochs用增强的数据集训练模型,接下来的几个epochs用未增强的数据集对模型进行fine-tuning;
第二阶段:用本文提出的基于CAM重采样方法对数据集进行平衡采样,之后用平衡数据集对模型的分类器进行重新训练。