前言: UT Austin Villa是近几年Robocup仿真3D项目中稳稳当当的世界冠军,他们每年拿了冠军之后都会发1到2篇论文来阐述他们的进步,其论文内容已经形成了固定模板。首先是Introduction,说一下他们近几年拿了多少个冠军等等,不用细看;然后是Domain Description,缀述一下RoboCup仿真3D的运行环境等等,不用细看;然后是Changes for 20xx,这个是介绍他们当年的进步的实现方法,重点看 ;再后面是Main Competition Results and Analysis、Technical Challenges,是各种秀战绩,不用细看。
一句话,只看Changes for 20xx就够了。
下面我把我们复现过程中可能会用到的一些部分进行了理解性的翻译。
论文中有些不明白的部分,我发邮件给了论文的作者,德克萨斯大学奥斯汀分校的教授Peter Stone,他帮我抄送给了他们团队的负责人,Patrick MacAlpine 博士后,从他那得到了非常耐心而详细的解答,非常感谢他们,并体会到了我们与世界冠军之间的巨大差距(例如原文标题为“品读”,现在改成了“拜读”)。
注: 本文只是一些注释和理解,原文还是要自己看几遍的。
一、2019年论文链接
论文主要内容及对一些部分的理解如下:
- 2019年robocup3D仿真比赛规则上新增的主要变化
- 加入了对自我碰撞的惩罚:*
One significant change for the 2019 RoboCup 3D Simulation League competition was penalizing self-collisions. While the simulator’s physics model can detect and simulate self-collisions—when a robot’s body part such as a leg or
arm collides with another part of its own body—having the physics model try
to process and handle the large number of self-collisions occurring during games
often leads to instability in the simulator causing it to crash. To preserve stability of the simulator self-collisions are purposely ignored by the physics model.
However, not modeling self-collisions can result in robots performing physically
impossible motions such as one leg passing through the other when kicking the
ball. In order to discourage teams from having robots with self-colliding behaviors, a new feature was added to the simulator this year to detect and penalize
self-collisions when they happen. This feature signals a self-collision as having
occurred if two body parts of a robot overlap by more than 0.04 meters, and
then all joints in any arm or leg of the robot involved in the self-collision are
frozen and not allowed to move for one second. Freezing the joints in an arm or
leg that has started to collide with another body part is an approximation of the
physics model preventing body parts from moving through each other, and also
detracts from the performance of the robot due to its limb being “numb” and immobile. After the second passes, the joints are unfrozen, and the robot is allowed to move its self-colliding body parts for two seconds without any self-collisions
being reported. This two second period, during which previously collided body
parts are no longer penalized and frozen for self-collisions, allows a robot time
to reposition its body to no longer have a self-collision.
加入了一个传球模式:
A player may initiate the pass play mode as long as the following conditions are all met:
– The current play mode is PlayOn.
– The agent is within 0.5 meters of the ball.
– No opponents are within a meter of the ball.
– The ball is stationary as measured by having a speed no greater than 0.05
meters per second.
– At least three seconds have passed since the last time a player’s team has
been in pass mode.
Once pass mode for a team has started the following happens:
– Players from the opponent team are prevented from getting within a meter
of the ball.
– The pass play mode ends as soon as a player touches the ball or four seconds
have passed.
– After pass mode has ended the team who initiated the pass mode is unable
to score for ten seconds—this prevents teams from trying to take a shot on
goal out of pass mode.
- 减少自我碰撞的方法
首先要确定哪些动作产生了自我碰撞通过跟其他不同队伍进行几千场比赛,将产生碰撞时的动作和球员编号记录下来。
下面是采用的策略:
1.手臂调整:大约一半有自我碰撞的踢球动作涉及到手臂,而在踢球动作中起主要作用的是腿,因此可以通过调整手臂的关节角度来避免自我碰撞,而不改变原先的踢球动作。
When a self-collision occurs, the simulator reports which body parts
of a robot collided with each other. For kicking skills the body parts that
matter the most are those in the legs, so if a robot’s arm is involved in a self-collision the arm’s movement can probably be adjusted without affecting
the kicking motion. Roughly half the kicking skills that had self-collisions
involved the robots’ arms in the self-collisions, so we were able to manually
adjust the arms’ joint angle positions to no longer self-collide while still
exhibiting the same kicking motion through the ball.
2.重新优化当前产生碰撞的动作:在很多情况下很难通过手动调节来避免动作中的自我碰撞,那么就以当前动作为起点,用cma-es算法重新进行优化,如果发生自我碰撞,就给球员的适应值上加上一个大的惩罚值。
In many cases it is not easy
to hand adjust the motions of a skill to avoid a self-collision as doing so fundamentally changes the performance of the skill (e.g. adjusting the position
of the legs of a robot for a kicking skill when the robot’s legs self-collide).
Instead of trying to fix things by hand, the current skill can be relearned
with CMA-ES using the current self-colliding behavior as a starting point
for learning, while also adding a large penalty value to the fitness of an agent
if it has any self-collisions while performing the optimization task it is trying
to learn.
3.如果当前的动作里含有很多自我碰撞,可能优化的时候就找不到不含有自我碰撞的动作,这时候就从跟当前动作相似的一个动作为起点开始优化
: If the previous strategy does
not work—possibly because the current behavior has too many self-collisions
such that it is hard to find a behavior that does not have self-collisions when
using the current self-colliding behavior as a starting point—one can instead
attempt to learn using a similar related skill (e.g. similar distance kick) that
has fewer collisions as a starting point for learning.
- 当某个动作只有很少的自碰撞,在学习试验中不经常出现,但是在比赛中仍然会产生不少次,那么就减小自碰撞阈值进行优化,例如假设比赛规定当胳膊与躯干交叠了10层时视为发生了自我碰撞,现在将其减小为5层进行优化,这样在优化时就能检测到该动作的自碰撞。
Some skills have
infrequent enough self-collisions that they do not always occur during a learning trial, but still experience a significant number of self-collisions during
games. It can be especially hard to reduce the number of self-collisions for
skills when self-collisions are not always detected during learning. As a way
to decrease the chance of the robot assuming body positions that are right on
the border of having self-collisions, one can decrease the allowed amount of
overlap between body parts in the simulator before a self-collision is considered to have occurred. By decreasing the amount of allowed overlap between
body parts during learning it is less likely that a learned behavior will have
self-collisions exceeding the actual allowed amount of overlap.
- 传球模式的策略
为了最好地利用传球模式的优点,球员必须小心地决定什么时候启用该模式。如果简单地在每一个满足传球模式的条件下都启用,会使我们必须要在传球之后10s才能射门;如果从不使用,又会使我们失去了在没有敌人的情况下踢球的机会。 - 下面是UT使用pass mode的策略:*
1.只在敌人离球1.25米以内时启用传球模式。因为如果敌人离得很远,不会对我们踢球造成威胁,这时候开启传球模式是没有必要的,而且越晚开启pass mode,留下的在pass mode最终结束之前的踢球时间就越长(我觉得这个的作用是,比如说我方球员现在离球0.4m,敌方球员离球1.2m,这时候开启pass mode的时间越晚,我方球员就可以走的离球更近,或者已经做出了踢球前的准备动作,这样可以节省在开启pass mode之后的踢球时间)。
Only activate pass mode when an opponent is within 1.25 meters of the
ball. Activating pass mode before the opponent is close is unnecessary as
the opponent is not yet a threat to interfere with a kick, and the later pass
mode is activated the later it will time out leaving more time to kick the ball
before pass mode eventually ends.
2.不要在球员离敌方球门足够近,可以直接射门得分时开启pass mode,否则必须要等10s才能射门。
Do not use pass mode when a player is close enough to take a shot on goal
and score. Goals cannot be scored for ten seconds after pass mode ends, so
it is better to attempt a shot and try to score than to pass the ball and then
have to wait ten seconds to score.
3.当球员不在球后面时,即使离敌方球门很近,可以直接射门,也要使用pass mode,因为球员从球前走到球后面的踢球点需要一定的时间,如果不开启pass mode敌人就会对我们踢球造成潜在威胁。
Do use pass mode if a player is not behind the ball even if the player is close
enough to the opponent’s goal to take a shot and score. The player will have
to take some time to walk around the ball to get in position to take a shot,
and at that point it is likely the opponent will have gotten close enough to
the ball to interfere with a potential shot.
二、2018年论文链接
2018年的主要进展:
- 可变距离的快速走踢:之前的踢球都是要走到一个固定的点,然后停下来执行踢球动作,可变距离的快速走踢可以避免机器人先在一个稳定的坐标点停下来,减少了踢球时间。相对于优化出一个可以调节距离的踢球动作,UT采用了优化出从5m到18m、每1m一个间隔的一个踢球动作集,可以用以不同距离的传球。
- 优化踢球的细节:* 把每一帧的动作中除了头部关节之外的所有关节的关节角度作为参数(大约260个。UT一共有12帧,可以大致推出踢球时间为0.24s),包括踢球前的站位坐标Xoffset和Yoffset,用cma-es算法和分层优化方法进行优化。优化任务是:踢10次,每次从球后面距离球1m的10个不同的坐标走到offset position,然后朝着一个坐标点踢,这个坐标点是由给定的一个方向和期望的距离算出来的,用一个fitness值来衡量踢球结果的好坏,最终的fitness值是10次尝试的平均值。
fitness的计算公式如下: 其中Penalty的情况是:
其中Penalty的情况是:1.摔倒
2.走过了,碰到了球或者没走够,错过了球
3.踢球时间太长 (超过12s没有接触球)造成超时
即产生Penalty时的fitness与球没有动时的结果一样。因为cma-es算法只使用训练中fitness值的顺序排序,因此不同踢球动作间fitness的相对误差不会造成影响。
优化代数:300代;
每代个体数:300个;
优化结果:fitness > -1,即球最终到达位置离目标点的平均距离小于一米。
优化顺序:先用已经有的长距离踢球参数作为种子,优化出一组好的长距离动作参数;然后依次减小优化的踢球距离,并将上一次的参数作为本次的种子。例如:用19m的参数作为种子优化18m的,再用18m的参数作为种子优化17m的。。。
- 深度学习传球策略
在2018年UT使用了基于深度学习的方法来训练传球策略。
数据集的获取方法: 设$S$是一个大小为m的数据集:${(x^i,y^i)}^m_{i=1}$,其中单输入$x^i$是一个49维的特征向量,用来表示比赛状态,即比赛模式、22个球员的坐标,球的坐标和潜在的传球坐标(我的理解是:比赛模式为1维,22个球员的x坐标和y坐标一共是44维,球的x坐标和y坐标一共2维,再加上潜在的传球x坐标和y坐标2维,一共49维);输出$y^i$是一个[0,1]之间的单标量值,用来表示潜在传球位置的值(译为“得分”更为恰当)。在数据采集过程中,先根据$x^i$将赛场恢复到一个确定的比赛状态,通过10次重复来确定$y^i$的值,在每一次采集时,如果在20s内进球了,就给一个+1的奖励,否则奖励为0,$y^i$就是这10次奖励的平均值。显然,对于每一种球员和球的站位状态,都有很多有效的传球位置;因此对于一种站位状态有很多的训练例子。(在这里,一个有效的传球位置是在距离球的初始坐标20m以内,而且球场范围内)
此外,下面的方法优化了数据集:
1.网络的输入是规范化的,具体地说,输入网络的球员坐标是按照球场的x坐标轴从左到右顺序排列的;
2.通过对数据预处理来确保对称。具体地说,如果球的y坐标是负值,就反转所有的y坐标以保证输入到神经网络的球的y坐标都是正值。这样相当于只用考虑球在球场上边一半时的情况,因而减少了一半的可能情况,提高了收敛速度。
优化传球的细节: 首先要确定合适的神经网络的大小,影响我们选择的有两个因素,一个是它是否会过拟合,另一个是它是否能在0.02s内完成计算。
下表是不同的神经网络大小所对应的平均花费时间、最大花费时间、和最大丢包数量,单位是毫秒。(最大丢包数量是sever和agent通信时丢失的消息量) UT选择的方案是上表第三种。
UT选择的方案是上表第三种。
下面是方案3的训练细节:
 一旦训练完成,这个网络就可以每时每刻根据当前的比赛状态计算出潜在传球位置的得分,机器人将传向得分最高的一个潜在传球位置。
一旦训练完成,这个网络就可以每时每刻根据当前的比赛状态计算出潜在传球位置的得分,机器人将传向得分最高的一个潜在传球位置。
以上是论文里的内容,看完之后我有一个疑问:
当我们收集数据集时,首先,将$x ^ i$设置为输入; 其次,我们需要根据$x ^ i$在RoboCup3D仿真平台上构建一个环境,并设计一种策略来测试它是否在20秒内达到目标。 最后,根据测试结果得到$y ^ i$。
我不明白的是,在上面的第二步中,如何设计策略?
Patrick MacAlpine 博士给出的详细回答(翻译了会变味,直接贴上原文):
三、2017年论文链接
2017年的主要进展:
- 快速走踢:之前的踢球都是要走到一个固定的点,然后停下来执行踢球动作,快速走踢可以避免机器人先在一个稳定的坐标点停下来,减少了踢球时间。
之前的踢球动作,最快的0.5s,但只能踢5m多一点,远踢可以踢到20m,但是需要2s时间去执行。 - 优化踢球的细节:* 把每一帧的动作的所有关节的关节角度作为参数(大约260个。UT一共有12帧,可以大致推出踢球时间为0.24s),用cma-es算法进行优化。机器人初始踢球动作参数被设置为,从他们之前的踢的最远的动作参数里面挑选出来12个周期的子集,其中要包括机器人的脚踢到球的部分。
优化代数:1000代;
每代个体数:300个;
fitness的计算公式如下:
(其思路是:球踢得越远越好 + 离目标点偏离的角度越小越好 + 跌倒就完蛋) 这样就能优化出来0.24s踢将近20m的动作。
这样就能优化出来0.24s踢将近20m的动作。
由于这个动作只用不到0.25秒的时间执行,因此机器人必须从步行位置开始进行踢球动作,并执行“步行踢”,原因是没有足够的时间让机器人在触击之前先站好再踢球。 在步行踢中,重要的是在开始踢球动作之前,将机器人的非踢球脚放在地面上,否则机器人可能会跌倒。 尝试步行踢时,机器人将在开始踢球之前一直等到其支撑腿落到地面上为止,可以用机器人支撑腿脚底的压力传感器来检测,如果其值大到一定范围,就视为已经放在了地面上。
四、2016年论文链接
2016年的主要进展:
- Marking
真看不懂 - 走到没有敌人的位置接应队友的传球(getting open,按文章里的意思翻译的):
我们希望踢球的目标点靠近队友,而且该队友周围没有敌人。之前的比赛中都是用广播来告知队友传球的目标点,在16年的比赛中,UT没有用这种方法,而是让球队阵型中的中前锋或者前锋根据公式(15年论文里的$score(target)$)计算出我方离球最近的球员将要踢向的目标点,然后提前走到这个目标点。根据该公式的思路(见下面15年论文部分),计算出的结果是远离敌方球员的,因而该方法可以让接应传球的我方球员走到一个没有敌人的位置。而在之前的方法中,接应队员所站的位置可能离敌人很近。 - 以踢球高度高度选择射门时的踢球动作
为防止射门时踢球高度超过球门而射出,UT测出了以不同的踢球动作进行踢球时,球在飞行过程中,其飞行高度高于球门的部分的距离(为方便理解画出了下图)。
例如:下图为type4的测试数据,每个动作进行了100次测试: 测出了这个数据,我们就能根据球离球门的距离,选择飞到球门时球的高度小于球门高度的踢球动作中踢球距离最远的那个动作,这样射门时可以力度最大而且不高出球门。
测出了这个数据,我们就能根据球离球门的距离,选择飞到球门时球的高度小于球门高度的踢球动作中踢球距离最远的那个动作,这样射门时可以力度最大而且不高出球门。 - 间接定位球
在我方发边界球或者在敌方发边界球两次碰球造成间接任意球时,采用下图所示的阵型,三个球员站在中场线靠后一点,三个前锋在靠近敌方球门的半场站一条线,发球队员根据公式(15年论文里的$score(target)$)选择一个最好的踢球目标点。在发球队员执行发球之前,也要等一会(10s)让队友有时间走到下图所示阵型中的位置。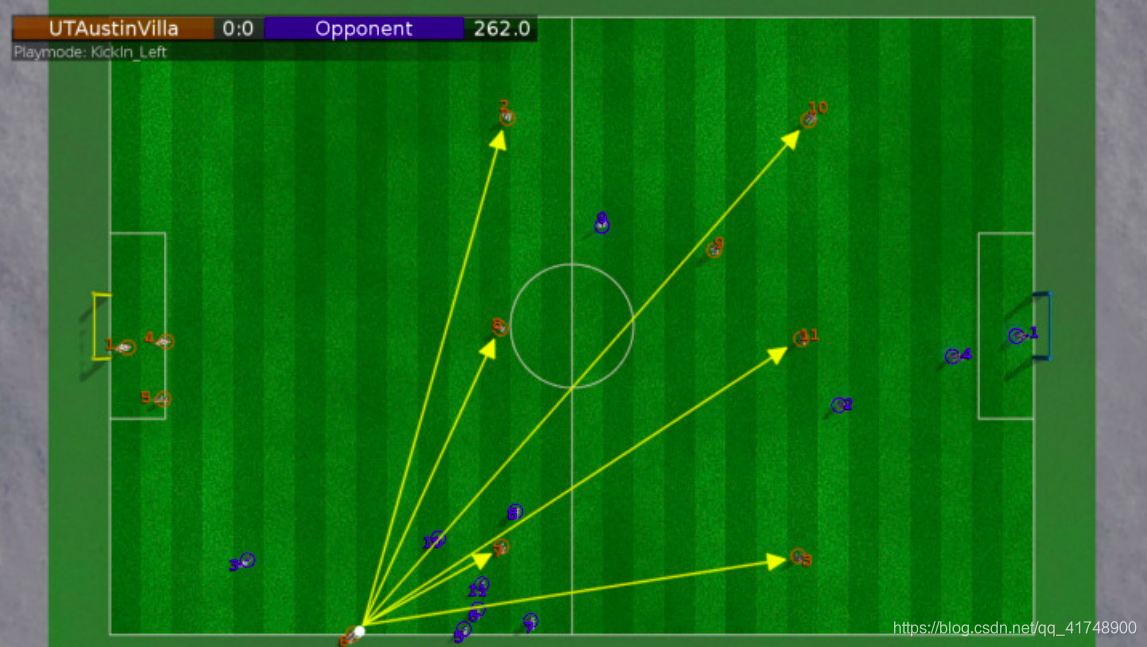
- 定向踢
(短期内实现的性价比较低) 定向踢可以让球踢到一个给定的方向,如图所示。
定向踢可以让球踢到一个给定的方向,如图所示。五、2015年论文链接
2015年的主要进展: - 可变距离的踢球动作:14年世界杯的时候,UT只有四种踢球动作:5m的快踢、15m的一个高踢和低踢、20m的远踢;这种踢球距离上的粗粒度限制了球可以被踢到的位置。我们希望球可以被踢到球场上的任意位置。
所以15年UT加入了13个新的踢球动作,从3m到15m每米一个,用cma-es算法和分层优化方法进行学习,优化完再对适应度最高的前300个参数集进行踢球测试,以检验其是否真的能踢到期望位置。
优化代数:400代;
每代个体数:150个;
有了不同距离的踢球动作,就可以选择很多踢球的目标点,如下图: 有这么多可以踢球的目标点,往哪踢呢?
有这么多可以踢球的目标点,往哪踢呢?
下面这个公式就是计算“往哪踢”的,输入是潜在踢球位置,输出是该位置的得分,因此可以输入很多潜在踢球位置,选择得分最高的那个点作为踢球目标点,如上图中带红圈的那个白点。
(其思路是:奖励能踢向敌方球门的、惩罚踢到敌方球员旁边的、奖励踢到我方球员身边的,公式中所有距离的单位都是m) 有了这种可变距离的踢球动作还有一个好处,之前在射门时经常会出现球从球门上面射过去,现在可以根据离球门的距离选择合适的踢球动作,可以达到直接飞进球门而不会从上面飞过的效果。
有了这种可变距离的踢球动作还有一个好处,之前在射门时经常会出现球从球门上面射过去,现在可以根据离球门的距离选择合适的踢球动作,可以达到直接飞进球门而不会从上面飞过的效果。 - 定位球(Set Plays在足球比赛中意为定位球,包括中圈开球、角球、任意球及球门球)
- 中圈开球:* 如果左右两侧没有敌人,如下图左,可以先踢到左侧或右侧,然后后面的队友跑过来直接射门;如果左右两侧有敌人,如下图右,则可以先回传给球场右侧的一个队友,然后由它再踢到球场的左侧,这时敌人已经被吸引到了右侧,可以右后面的队友跑过来直接射门。
 我方角球: 如下图所示,我方发角球时,先判断中场的3个队友周围有没有敌人,哪个没有就传给哪个,然后直接射门;如果三个身边都有敌人,就传到门前,门前也有队友在等待。
我方角球: 如下图所示,我方发角球时,先判断中场的3个队友周围有没有敌人,哪个没有就传给哪个,然后直接射门;如果三个身边都有敌人,就传到门前,门前也有队友在等待。 当然,上面的定位球策略都需要准确的可变距离的踢球动作作为基础,而且接近球和踢球的速度必须要快,因为一个定位球的发球时间只有15s。
当然,上面的定位球策略都需要准确的可变距离的踢球动作作为基础,而且接近球和踢球的速度必须要快,因为一个定位球的发球时间只有15s。 - 踢球决策分类器
(短期内实现的性价比较低)
在我们考虑往哪踢之前,首先要决定我们采用踢球还是带球。在14年UT的策略是当敌人离球的距离小于2m时就一直带球。
15年UT训练出了一个逻辑回归分类器来预测当前情况下成功踢球的概率。 - 具体方法为:* 和敌方球队踢很多场比赛,在比赛中让我方球员只踢球而不带球,记录每次尝试踢球时球场的下列状态特征,并根据每次尝试踢球是否成功来标记这次踢球时球场的状态特征是好的还是坏的。
 训练好的分类器的输出是进行一次踢球尝试成功的概率,要设置一个阈值,当踢球成功的概率高于该阈值时选择踢球,那么怎么确定这个阈值的大小呢?
训练好的分类器的输出是进行一次踢球尝试成功的概率,要设置一个阈值,当踢球成功的概率高于该阈值时选择踢球,那么怎么确定这个阈值的大小呢?
跟不同的球队进行100场比赛,测试阈值为不同的值时的平均净胜球数、踢球次数、进球数及平局和输球的可能性,可以根据这些数据选择出一个最好的阈值。
附: UT所有文献的网址
值得一提:
入门RoboCup仿真3D的必读材料:用户手册,里面的通信部分可以参考:RoboCup仿真3D底层通信模块介绍(一)、RoboCup仿真3D底层通信模块介绍(二)
上手Robocup仿真3D的必读材料:UT开源底层的详细介绍